This is the second tutorial on the Spark RDDs Vs DataFrames vs SparkSQL blog post series. The first one is available at DataScience+. In the first part, I showed how to retrieve, sort and filter data using Spark RDDs, DataFrames, and SparkSQL. In this tutorial, we will see how to work with multiple tables in Spark the RDD way, the DataFrame way and with SparkSQL.
If you like this tutorial series, check also my other recent blog posts on Spark on Analyzing the Bible and the Quran using Spark and Spark DataFrames: Exploring Chicago Crimes. The data and the notebooks can be downloaded from my GitHub repository. The size of the data is not large, however, the same code works for large volume as well. Therefore, we can practice with this dataset to master the functionalities of Spark.
For this tutorial, we will work with the SalesLTProduct.txt, SalesLTSalesOrderHeader.txt, SalesLTCustomer.txt, SalesLTAddress.txt and SalesLTCustomerAddress.txt datasets. Let’s answer a couple of questions using Spark Resilient Distiributed (RDD) way, DataFrame way and SparkSQL.
from pyspark import SparkContext, SparkConf
from pyspark.sql import SQLContext
conf = SparkConf().setAppName("miniProject").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
sqlcontext = SQLContext(sc)
Retrieve customer orders
As an initial step towards generating invoice report, write a query that returns the company name from the SalesLTCustomer.txt, and the sales order ID and total due from the SalesLTSalesOrderHeader.txt.
RDD way
orderHeader = sc.textFile("SalesLTSalesOrderHeader.txt")
customer = sc.textFile("SalesLTCustomer.txt")
Now, let’s have the column names and the contents separated.
customer_header = customer.first() customer_rdd = customer.filter(lambda line: line != customer_header) orderHeader_header = orderHeader.first() orderHeader_rdd = orderHeader.filter(lambda line: line != orderHeader_header)
We need only CustomerID and ComapanyName from the customers RDD. From the orderHeader RDD we need CustomerID,SalesOrderID and TotalDue then we are joining the two RDD using inner join.Finally, we are displaying 10 companies with the highest amout due.
customer_rdd1 = customer_rdd.map(lambda line: (line.split("\t")[0], #CustomerID
line.split("\t")[7] #CompanyName
))
orderHeader_rdd1 = orderHeader_rdd.map(lambda line: (line.split("\t")[10], #CustomerID
(line.split("\t")[0], #SalesOrderID
float(line.split("\t")[-4]) # TotalDue
)))
invoice1 = customer_rdd1.join(orderHeader_rdd1)
invoice1.takeOrdered(10, lambda x: -x[1][1][1])
[('29736', ('Action Bicycle Specialists', ('71784', 119960.824))),
('30050', ('Metropolitan Bicycle Supply', ('71936', 108597.9536))),
('29546', ('Bulk Discount Store', ('71938', 98138.2131))),
('29957', ('Eastside Department Store', ('71783', 92663.5609))),
('29796', ('Riding Cycles', ('71797', 86222.8072))),
('29929', ('Many Bikes Store', ('71902', 81834.9826))),
('29932', ('Instruments and Parts Company', ('71898', 70698.9922))),
('29660', ('Extreme Riding Supplies', ('71796', 63686.2708))),
('29938', ('Trailblazing Sports', ('71845', 45992.3665))),
('29485', ('Professional Sales and Service', ('71782', 43962.7901)))]
If we want, once we collect the RDD resulting from our transformations and actions, we can use other Python packages to visualize our data.
import pandas as pd
top10 = invoice1.takeOrdered(10, lambda x: -x[1][1][1])
companies = [x[1][0] for x in top10]
total_due = [x[1][1][1] for x in top10]
top10_dict = {"companies": companies, "total_due":total_due}
top10_pd = pd.DataFrame(top10_dict)
import matplotlib.pyplot as plt
%matplotlib inline
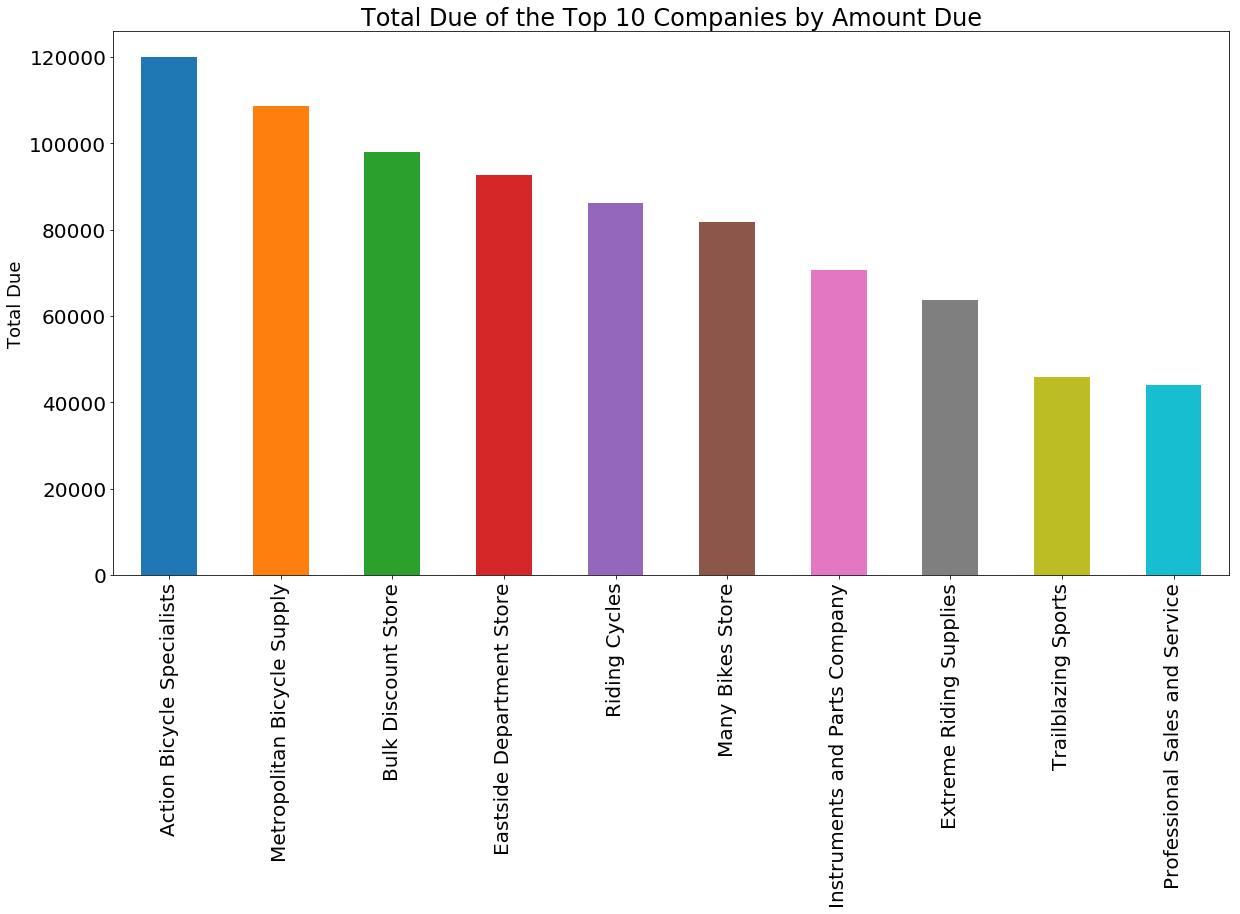
top10_pd.plot(figsize = (20, 10),kind = "bar", legend = False, x = "companies", y = "total_due")
plt.xlabel("")
plt.ylabel("Total Due", fontsize = 18)
plt.title("Total Due of the Top 10 Companies by Amount Due", fontsize = 24)
plt.xticks(size = 20)
plt.yticks(size = 20)
plt.show()
Gives this plot:
DataFrame way
First, we create DataFrames from the RDDs by using the first row as schema.
customer_df = sqlcontext.createDataFrame(customer_rdd.map(lambda line: line.split("\t")),
schema = customer.first().split("\t"))
orderHeader_df = sqlcontext.createDataFrame(orderHeader_rdd.map(lambda line: line.split("\t")),
schema = orderHeader.first().split("\t"))
Now, let’s join the two DataFrames using the CustomerID column. We need to use inner join here. We are ordering the rows by TotalDue column in descending order but our result does not look normal. As we can see from the schema of the joined DataFrame, the TotalDue column is string. Therefore, we have to change that column to numeric field.
joined = customer_df.join(orderHeader_df, 'CustomerID', how = "inner")
joined.select(["CustomerID", 'CompanyName','SalesOrderID','TotalDue']).orderBy("TotalDue", ascending = False).show(10, truncate = False)
+----------+-----------------------------+------------+----------+
|CustomerID|CompanyName |SalesOrderID|TotalDue |
+----------+-----------------------------+------------+----------+
|29546 |Bulk Discount Store |71938 |98138.2131|
|29847 |Good Toys |71774 |972.785 |
|29957 |Eastside Department Store |71783 |92663.5609|
|30072 |West Side Mart |71776 |87.0851 |
|29796 |Riding Cycles |71797 |86222.8072|
|29929 |Many Bikes Store |71902 |81834.9826|
|29531 |Remarkable Bike Store |71935 |7330.8972 |
|29932 |Instruments and Parts Company|71898 |70698.9922|
|30033 |Transport Bikes |71856 |665.4251 |
|29660 |Extreme Riding Supplies |71796 |63686.2708|
+----------+-----------------------------+------------+----------+
joined.printSchema() root |-- CustomerID: string (nullable = true) |-- NameStyle: string (nullable = true) |-- Title: string (nullable = true) |-- FirstName: string (nullable = true) |-- MiddleName: string (nullable = true) |-- LastName: string (nullable = true) |-- Suffix: string (nullable = true) |-- CompanyName: string (nullable = true) |-- SalesPerson: string (nullable = true) |-- EmailAddress: string (nullable = true) |-- Phone: string (nullable = true) |-- PasswordHash: string (nullable = true) |-- PasswordSalt: string (nullable = true) |-- rowguid: string (nullable = true) |-- ModifiedDate: string (nullable = true) |-- SalesOrderID: string (nullable = true) |-- RevisionNumber: string (nullable = true) |-- OrderDate: string (nullable = true) |-- DueDate: string (nullable = true) |-- ShipDate: string (nullable = true) |-- Status: string (nullable = true) |-- OnlineOrderFlag: string (nullable = true) |-- SalesOrderNumber: string (nullable = true) |-- PurchaseOrderNumber: string (nullable = true) |-- AccountNumber: string (nullable = true) |-- ShipToAddressID: string (nullable = true) |-- BillToAddressID: string (nullable = true) |-- ShipMethod: string (nullable = true) |-- CreditCardApprovalCode: string (nullable = true) |-- SubTotal: string (nullable = true) |-- TaxAmt: string (nullable = true) |-- Freight: string (nullable = true) |-- TotalDue: string (nullable = true) |-- Comment: string (nullable = true) |-- rowguid: string (nullable = true) |-- ModifiedDate: string (nullable = true)
from pyspark.sql.functions import col, udf from pyspark.sql.types import DoubleType convert = udf(lambda x: float(x), DoubleType())
Now, let’s change the TotalDue column to numeric.
joined2 = joined.withColumn('Total_Due',convert(col("TotalDue"))).drop("TotalDue")
joined2.dtypes[-1] # we have created a new column with double type
('Total_Due', 'double')
joined2.select(["CustomerID", 'CompanyName','SalesOrderID','Total_Due'])\
.orderBy("Total_Due", ascending = False).show(10, truncate = False)
+----------+------------------------------+------------+-----------+
|CustomerID|CompanyName |SalesOrderID|Total_Due |
+----------+------------------------------+------------+-----------+
|29736 |Action Bicycle Specialists |71784 |119960.824 |
|30050 |Metropolitan Bicycle Supply |71936 |108597.9536|
|29546 |Bulk Discount Store |71938 |98138.2131 |
|29957 |Eastside Department Store |71783 |92663.5609 |
|29796 |Riding Cycles |71797 |86222.8072 |
|29929 |Many Bikes Store |71902 |81834.9826 |
|29932 |Instruments and Parts Company |71898 |70698.9922 |
|29660 |Extreme Riding Supplies |71796 |63686.2708 |
|29938 |Trailblazing Sports |71845 |45992.3665 |
|29485 |Professional Sales and Service|71782 |43962.7901 |
+----------+------------------------------+------------+-----------+
only showing top 10 rows
The result above is the same as the result we got using the RDD way above.
Running SQL Queries Programmatically
First, let’s create a local temporary view of the DataFrames and we can use normal SQL commands to get the 10 companies with the highest amount due.
orderHeader_df.createOrReplaceTempView("orderHeader_table")
customer_df.createOrReplaceTempView("customer_table")
sqlcontext.sql("SELECT c.CustomerID, c.CompanyName,oh.SalesOrderID,cast(oh.TotalDue AS DECIMAL(10,4)) \
FROM customer_table AS c INNER JOIN orderHeader_table AS OH ON c.CustomerID=oh.CustomerID \
ORDER BY TotalDue DESC LIMIT 10").show(10, truncate = False)
We see that the results we got using the above three methods, RDD way, DataFrame and with SparkSQL, are the same.
Retrieve customer orders with addresses
Extend your customer orders query to include the Main Office address for each customer, including the full street address, city, state or province, and country or region. Note that each customer can have multiple addresses in the SalesLTAddress.txt, so the SalesLTCustomerAddress.txt dataset enables a many-to-many relationship between customers and addresses. Your query will need to include both of these datasets and should filter the join to SalesLTCustomerAddress.txt so that only Main Office addresses are included.
RDD way
I am not repeating some of the steps, I did in question 1 above.
As we can see below, the datasets for this question are also tab delimited.
address = sc.textFile("SalesLTAddress.txt")
customer_address = sc.textFile("SalesLTCustomerAddress.txt")
customer_address.first()
'CustomerID\tAddressID\tAddressType\trowguid\tModifiedDate'
address.first() 'AddressID\tAddressLine1\tAddressLine2\tCity\tStateProvince\tCountryRegion\tPostalCode\trowguid\tModifiedDate'
Removing the column names from the RDDs.
address_header = address.first() address_rdd = address.filter(lambda line: line != address_header ) customer_address_header = customer_address.first() customer_address_rdd = customer_address.filter(lambda line: line != customer_address_header)
Include only those with AddressType of Main Office.
Split the lines and retain only fields of interest.
customer_address_rdd1 = customer_address_rdd.filter(lambda line: line.split("\t")[2] =="Main Office").map(lambda line: (line.split("\t")[0], #CustomerID
line.split("\t")[1], #AddressID
))
address_rdd1 = address_rdd.map(lambda line: (line.split("\t")[0], #AddressID
(line.split("\t")[1], #AddressLine1
line.split("\t")[3], #City
line.split("\t")[4], #StateProvince
line.split("\t")[5] #CountryRegion
)))
We can now join them.
rdd = customer_rdd1.join(orderHeader_rdd1).join(customer_address_rdd1).map(lambda line: (line[1][1], # AddressID
(line[1][0][0], # Company
line[1][0][1][0],# SalesOrderID
line[1][0][1][1]# TotalDue
)))
final_rdd = rdd.join(address_rdd1)
Let’s rearrange the columns.
final_rdd2 = final_rdd.map(lambda line: (line[1][0][0], # company
float(line[1][0][2]), # TotalDue
line[1][1][0], # Address 1
line[1][1][1], # City
line[1][1][2], # StateProvince
line[1][1][3] # CountryRegion
))
Let’s see 10 companies with the highest amount due.
final_rdd2.takeOrdered(10, lambda x: -x[1])
[('Action Bicycle Specialists',
119960.824,
'Warrington Ldc Unit 25/2',
'Woolston',
'England',
'United Kingdom'),
('Metropolitan Bicycle Supply',
108597.9536,
'Paramount House',
'London',
'England',
'United Kingdom'),
('Bulk Discount Store',
98138.2131,
'93-2501, Blackfriars Road,',
'London',
'England',
'United Kingdom'),
('Eastside Department Store',
92663.5609,
'9992 Whipple Rd',
'Union City',
'California',
'United States'),
('Riding Cycles',
86222.8072,
'Galashiels',
'Liverpool',
'England',
'United Kingdom'),
('Many Bikes Store',
81834.9826,
'Receiving',
'Fullerton',
'California',
'United States'),
('Instruments and Parts Company',
70698.9922,
'Phoenix Way, Cirencester',
'Gloucestershire',
'England',
'United Kingdom'),
('Extreme Riding Supplies',
63686.2708,
'Riverside',
'Sherman Oaks',
'California',
'United States'),
('Trailblazing Sports',
45992.3665,
'251340 E. South St.',
'Cerritos',
'California',
'United States'),
('Professional Sales and Service',
43962.7901,
'57251 Serene Blvd',
'Van Nuys',
'California',
'United States')]
DataFrame Way
Now, can create DataFrames from the RDDs and perform the joins.
address_df = sqlcontext.createDataFrame(address_rdd.map(lambda line: line.split("\t")),
schema = address_header.split("\t") )
customer_address_df = sqlcontext.createDataFrame(customer_address_rdd .map(lambda line: line.split("\t")),
schema = customer_address_header.split("\t") )
We can see the schema of each DataFrame.
address_df.printSchema() root |-- AddressID: string (nullable = true) |-- AddressLine1: string (nullable = true) |-- AddressLine2: string (nullable = true) |-- City: string (nullable = true) |-- StateProvince: string (nullable = true) |-- CountryRegion: string (nullable = true) |-- PostalCode: string (nullable = true) |-- rowguid: string (nullable = true) |-- ModifiedDate: string (nullable = true)
customer_address_df.printSchema() root |-- CustomerID: string (nullable = true) |-- AddressID: string (nullable = true) |-- AddressType: string (nullable = true) |-- rowguid: string (nullable = true) |-- ModifiedDate: string (nullable = true)
Now, we can finally join the DataFrames but to order the rows based on the total amount due, we have to first convert that column to numeric.
joined = (customer_df.join(orderHeader_df, 'CustomerID', how = "inner")
.join(customer_address_df,'CustomerID', how = "inner" )
.join(address_df,'AddressID', how = "inner" ))
joined2 = joined.withColumn('Total_Due',convert(col("TotalDue"))).drop("TotalDue").filter(joined['AddressType']=="Main Office")
joined2.select(['CompanyName','Total_Due',
'AddressLine1','City',
'StateProvince','CountryRegion']).orderBy('Total_Due', ascending = False).show(10, truncate = False)
The answer using the RDD way is the same as the answer we got above using the RDD way.
Running SQL Queries Programmatically
As shown below, the answer using SQL, after creating a local temporary view, also gives the same answer as the RDD way and DataFrame way above.
address_df.createOrReplaceTempView("address_table")
customer_address_df.createOrReplaceTempView("customer_address_table")
sqlcontext.sql("SELECT c.CompanyName,cast(oh.TotalDue AS DECIMAL(10,4)), a.AddressLine1, \
a.City, a.StateProvince, a.CountryRegion FROM customer_table AS c \
INNER JOIN orderHeader_table AS oh ON c.CustomerID = oh.CustomerID \
INNER JOIN customer_address_table AS ca ON c.CustomerID = ca.CustomerID AND AddressType = 'Main Office' \
INNER JOIN address_table AS a ON ca.AddressID = a.AddressID \
ORDER BY TotalDue DESC LIMIT 10").show(truncate = False)
Retrieve a list of all customers and their orders
The sales manager wants a list of all customer companies and their contacts (first name and last name), showing the sales order ID and total due for each order they have placed. Customers who have not placed any orders should be included at the bottom of the list with NULL values for the order ID and total due.
RDD way
Let’s create the RDDs, select the fields of interest and join them.
customer_header = customer.first() customer_rdd = customer.filter(lambda line: line != customer_header) orderHeader_header = orderHeader.first() orderHeader_rdd = orderHeader.filter(lambda line: line != orderHeader_header)
customer_rdd1 = customer_rdd.map(lambda line: (line.split("\t")[0], #CustomerID
(line.split("\t")[3], #FirstName
line.split("\t")[5] #LastName
)))
orderHeader_rdd1 = orderHeader_rdd.map(lambda line: (line.split("\t")[10], # CustomerID
(line.split("\t")[0], # SalesOrderID
line.split("\t")[-4] # TotalDue
)))
We have to re-arrange customers that have made orders and those that have not ordered separetly and then uinon them at the end.
joined = customer_rdd1.leftOuterJoin(orderHeader_rdd1) NonNulls = joined.filter(lambda line: line[1][1]!=None) Nulls = joined.filter(lambda line: line[1][1]==None)
Let’s see the data structures for both of them.
NonNulls.take(5)
[('30113', (('Raja', 'Venugopal'), ('71780', '42452.6519'))),
('30089', (('Michael John', 'Troyer'), ('71815', '1261.444'))),
('29485', (('Catherine', 'Abel'), ('71782', '43962.7901'))),
('29638', (('Rosmarie', 'Carroll'), ('71915', '2361.6403'))),
('29938', (('Frank', 'Campbell'), ('71845', '45992.3665')))]
Let’s rearrage them.
NonNulls2 = NonNulls.map(lambda line: (line[0], line[1][0][0],line[1][0][1], line[1][1][0], float(line[1][1][1])))
NonNulls2.first()
('30113', 'Raja', 'Venugopal', '71780', 42452.6519)
Similarly, let’s rearrange the Nulls RDD.
Nulls.take(5)
[('190', (('Mark', 'Lee'), None)),
('30039', (('Robert', 'Stotka'), None)),
('110', (('Kendra', 'Thompson'), None)),
('29832', (('Jésus', 'Hernandez'), None)),
('473', (('Kay', 'Krane'), None))]
Nulls2 = Nulls.map(lambda line: (line[0], line[1][0][0],line[1][0][1], "NULL", "NULL"))
Now, we can union them and see the top five and bottom five as below.
union_rdd = NonNulls2.union(Nulls2)
DataFrame
Now, we let’s answer it the question the DataFrame approach.
customer_df = sqlcontext.createDataFrame(customer_rdd.map(lambda line: line.split("\t")),
schema = customer.first().split("\t"))
orderHeader_df = sqlcontext.createDataFrame(orderHeader_rdd.map(lambda line: line.split("\t")),
schema = orderHeader.first().split("\t"))
customer_df.printSchema() root |-- CustomerID: string (nullable = true) |-- NameStyle: string (nullable = true) |-- Title: string (nullable = true) |-- FirstName: string (nullable = true) |-- MiddleName: string (nullable = true) |-- LastName: string (nullable = true) |-- Suffix: string (nullable = true) |-- CompanyName: string (nullable = true) |-- SalesPerson: string (nullable = true) |-- EmailAddress: string (nullable = true) |-- Phone: string (nullable = true) |-- PasswordHash: string (nullable = true) |-- PasswordSalt: string (nullable = true) |-- rowguid: string (nullable = true) |-- ModifiedDate: string (nullable = true)
orderHeader_df.printSchema() root |-- SalesOrderID: string (nullable = true) |-- RevisionNumber: string (nullable = true) |-- OrderDate: string (nullable = true) |-- DueDate: string (nullable = true) |-- ShipDate: string (nullable = true) |-- Status: string (nullable = true) |-- OnlineOrderFlag: string (nullable = true) |-- SalesOrderNumber: string (nullable = true) |-- PurchaseOrderNumber: string (nullable = true) |-- AccountNumber: string (nullable = true) |-- CustomerID: string (nullable = true) |-- ShipToAddressID: string (nullable = true) |-- BillToAddressID: string (nullable = true) |-- ShipMethod: string (nullable = true) |-- CreditCardApprovalCode: string (nullable = true) |-- SubTotal: string (nullable = true) |-- TaxAmt: string (nullable = true) |-- Freight: string (nullable = true) |-- TotalDue: string (nullable = true) |-- Comment: string (nullable = true) |-- rowguid: string (nullable = true) |-- ModifiedDate: string (nullable = true)
We can see samples of those that have made orders and those that have not as below.
joined = customer_df.join(orderHeader_df, 'CustomerID', how = "left")
joined.select(["CustomerID", 'FirstName','LastName','SalesOrderNumber','TotalDue'])\
.orderBy("TotalDue", ascending = False).show(10, truncate = False)
+----------+-----------+--------+----------------+----------+
|CustomerID|FirstName |LastName|SalesOrderNumber|TotalDue |
+----------+-----------+--------+----------------+----------+
|29546 |Christopher|Beck |SO71938 |98138.2131|
|29847 |David |Hodgson |SO71774 |972.785 |
|29957 |Kevin |Liu |SO71783 |92663.5609|
|30072 |Andrea |Thomsen |SO71776 |87.0851 |
|29796 |Jon |Grande |SO71797 |86222.8072|
|29929 |Jeffrey |Kurtz |SO71902 |81834.9826|
|29531 |Cory |Booth |SO71935 |7330.8972 |
|29932 |Rebecca |Laszlo |SO71898 |70698.9922|
|30033 |Vassar |Stern |SO71856 |665.4251 |
|29660 |Anthony |Chor |SO71796 |63686.2708|
+----------+-----------+--------+----------------+----------+
only showing top 10 rows
joined.select(["CustomerID", 'FirstName','LastName','SalesOrderNumber','TotalDue'])\
.orderBy("TotalDue", ascending = True).show(10, truncate = False)
+----------+---------+-----------+----------------+--------+
|CustomerID|FirstName|LastName |SalesOrderNumber|TotalDue|
+----------+---------+-----------+----------------+--------+
|29539 |Josh |Barnhill |null |null |
|29573 |Luis |Bonifaz |null |null |
|29865 |Lucio |Iallo |null |null |
|29978 |Ajay |Manchepalli|null |null |
|451 |John |Emory |null |null |
|124 |Yuhong |Li |null |null |
|29580 |Richard |Bready |null |null |
|7 |Dominic |Gash |null |null |
|29525 |Teresa |Atkinson |null |null |
|29733 |Shannon |Elliott |null |null |
+----------+---------+-----------+----------------+--------+
only showing top 10 rows
Running SQL Queries Programmatically
Below, I have shown samples of those that have made orders and those that have not using normal SQL commands.
orderHeader_df.createOrReplaceTempView("orderHeader_table")
customer_df.createOrReplaceTempView("customer_table")
sqlcontext.sql("SELECT c.CustomerID, c.FirstName,c.LastName, oh.SalesOrderID,cast(oh.TotalDue AS DECIMAL(10,4)) \
FROM customer_table AS c LEFT JOIN orderHeader_table AS oh ON c.CustomerID = oh.CustomerID \
ORDER BY TotalDue DESC LIMIT 10").show(truncate = False)
sqlcontext.sql("SELECT c.CustomerID, c.FirstName,c.LastName, oh.SalesOrderID,cast(oh.TotalDue AS DECIMAL(10,4)) \
FROM customer_table AS c LEFT JOIN orderHeader_table AS oh ON c.CustomerID = oh.CustomerID \
ORDER BY TotalDue ASC LIMIT 10").show(truncate = False)
Retrieve a list of customers with no address
A sales employee has noticed that Adventure Works does not have address information for all customers. You must write a query that returns a list of customer IDs, company names, contact names (first name and last name), and phone numbers for customers with no address stored in the database.
RDD way
customer_header = customer.first()
customer_rdd = customer.filter(lambda line: line != customer_header)
customer_address_header = customer_address.first()
customer_address_rdd = customer_address.filter(lambda line: line != customer_address_header)
customer_rdd1 = customer_rdd.map(lambda line: (line.split("\t")[0], #CustomerID
(line.split("\t")[3], #FirstName
line.split("\t")[5], #LastName
line.split("\t")[7], #CompanyName
line.split("\t")[9], #EmailAddress
line.split("\t")[10] #Phone
)))
customer_address_rdd1 = customer_address_rdd.map(lambda line: (line.split("\t")[0],line.split("\t")[1]))
First, let’s join the customer data to the customer address dataset.Then, we will filter the RDD to include those that do not have address information.
joined = customer_rdd1.leftOuterJoin(customer_address_rdd1)
DataFrame way
After getting those who don’t have address information, below I am displaying 10 rows.
customer_df = sqlcontext.createDataFrame(customer_rdd.map(lambda line: line.split("\t")),
schema = customer.first().split("\t"))
customer_address_df = sqlcontext.createDataFrame(customer_address_rdd.map(lambda line: line.split("\t")),
schema = customer_address_header.split("\t"))
joined = customer_df.join(customer_address_df, 'CustomerID','left')
joined.filter(col("AddressID").isNull()).\
select(['FirstName','LastName','CompanyName','EmailAddress','Phone'])\
.show(10, truncate = False)
Running SQL Queries Programmatically
Using SQL also gives the same answers as the DataFrame approach shown above.
customer_address_df.createOrReplaceTempView("customer_address_table")
customer_df.createOrReplaceTempView("customer_table")
sqlcontext.sql("SELECT c.FirstName,c.LastName, c.CompanyName,c.EmailAddress,c.Phone \
FROM customer_table AS c LEFT JOIN customer_address_table AS ca ON c.CustomerID = ca.CustomerID \
WHERE ca.AddressID IS NULL").show(10, truncate = False)
This is enough for today. In the next part of the Spark RDDs Vs DataFrames vs SparkSQL tutorial series, I will come with a different topic. If you have any questions or suggestions, feel free to drop them below.
Hello,
Can you please explain this line
invoice1.takeOrdered(10, lambda x: -x[1][1][1])
What values does “-x[1][1][1]” retrieve?