This post presents a reference implementation of an employee turnover analysis project that is built by using Python’s Scikit-Learn library. In this article, we introduce Logistic Regression, Random Forest, and Support Vector Machine. We also measure the accuracy of models that are built by using Machine Learning, and we assess directions for further development. And we will do all of the above in Python. Let’s get started!
Data Preprocessing
The data was downloaded from Kaggle. It is pretty straightforward. Each row represents an employee; each column contains employee attributes:
* satisfaction_level (0–1)
* last_evaluation (Time since last evaluation in years)
* number_projects (Number of projects completed while at work)
* average_monthly_hours (Average monthly hours at workplace)
* time_spend_company (Time spent at the company in years)
* Work_accident (Whether the employee had a workplace accident)
* left (Whether the employee left the workplace or not (1 or 0))
* promotion_last_5years (Whether the employee was promoted in the last five years)
* sales (Department in which they work for)
* salary (Relative level of salary)
import pandas as pd
hr = pd.read_csv('HR.csv')
col_names = hr.columns.tolist()
print("Column names:")
print(col_names)
print("\nSample data:")
hr.head()
Column names:
['satisfaction_level', 'last_evaluation', 'number_project', 'average_montly_hours', 'time_spend_company', 'Work_accident', 'left', 'promotion_last_5years', 'sales', 'salary']
Gives this table:

Rename column name from “sales” to “department”
hr=hr.rename(columns = {'sales':'department'})
The type of the column can be found out as follows:
hr.dtypes satisfaction_level float64 last_evaluation float64 number_project int64 average_montly_hours int64 time_spend_company int64 Work_accident int64 left int64 promotion_last_5years int64 department object salary object dtype: object
Our data is pretty clean, no missing values
hr.isnull().any() satisfaction_level False last_evaluation False number_project False average_montly_hours False time_spend_company False Work_accident False left False promotion_last_5years False department False salary False dtype: bool
The data contains 14,999 employees and 10 features.
hr.shape (14999, 10)
The “left” column is the outcome variable recording 1 and 0. 1 for employees who left the company and 0 for those who didn’t.
The department column of the dataset has many categories and we need to reduce the categories for a better modeling. The department column has the following categories:
hr['department'].unique()
array(['sales', 'accounting', 'hr', 'technical', 'support', 'management',
'IT', 'product_mng', 'marketing', 'RandD'], dtype=object)
Let us combine “technical”, “support” and “IT” these three together and call them “technical”.
import numpy as np hr['department']=np.where(hr['department'] =='support', 'technical', hr['department']) hr['department']=np.where(hr['department'] =='IT', 'technical', hr['department'])
After the change, this is how the department categories look:
print(hr['department'].unique()) ['sales' 'accounting' 'hr' 'technical' 'management' 'product_mng' 'marketing' 'RandD']
Data Exploration
First of all, let us find out the number of employees who left the company and those who didn’t:
hr['left'].value_counts() 0 11428 1 3571 Name: left, dtype: int64
There are 3571 employees left and 11428 employees stayed in our data.
Let us get a sense of the numbers across these two classes:
hr.groupby('left').mean()
Gives this table:

Several observations:
* The average satisfaction level of employees who stayed with the company is higher than that of the employees who left.
* The average monthly work hours of employees who left the company is more than that of the employees who stayed.
* The employees who had workplace accidents are less likely to leave than that of the employee who did not have workplace accidents.
* The employees who were promoted in the last five years are less likely to leave than those who did not get a promotion in the last five years.
We can calculate categorical means for categorical variables such as department and salary to get a more detailed sense of our data like so:
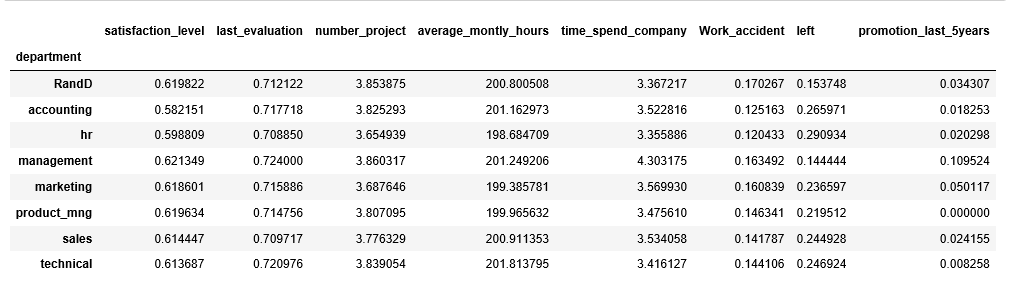
hr.groupby('department').mean()
Gives this table:
hr.groupby('salary').mean()
Gives this table:

Data Visualization
Let us visualize our data to get a much clearer picture of the data and the significant features.
Bar chart for department employee work for and the frequency of turnover
%matplotlib inline
import matplotlib.pyplot as plt
pd.crosstab(hr.department,hr.left).plot(kind='bar')
plt.title('Turnover Frequency for Department')
plt.xlabel('Department')
plt.ylabel('Frequency of Turnover')
plt.savefig('department_bar_chart')
Gives this plot:

It is evident that the frequency of employee turnover depends a great deal on the department they work for. Thus, department can be a good predictor of the outcome variable.
Bar chart for employee salary level and the frequency of turnover
table=pd.crosstab(hr.salary, hr.left)
table.div(table.sum(1).astype(float), axis=0).plot(kind='bar', stacked=True)
plt.title('Stacked Bar Chart of Salary Level vs Turnover')
plt.xlabel('Salary Level')
plt.ylabel('Proportion of Employees')
plt.savefig('salary_bar_chart')
Gives this plot:
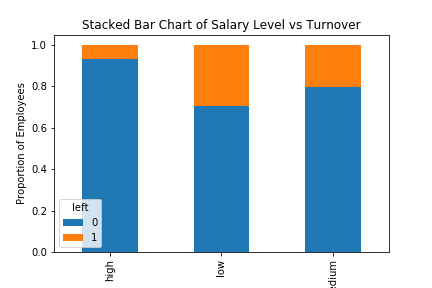
The proportion of the employee turnover depends a great deal on their salary level; hence, salary level can be a good predictor in predicting the outcome.
Histograms are often one of the most helpful tools we can use for numeric variables during the exploratory phrase.
Histogram of numeric variables
num_bins = 10
hr.hist(bins=num_bins, figsize=(20,15))
plt.savefig("hr_histogram_plots")
plt.show()
Gives this plot:

Creating Dummy Variables for Categorical Variables
There are two categorical variables (department, salary) in the dataset and they need to be converted to dummy variables before they can be used for modelling.
cat_vars=['department','salary']
for var in cat_vars:
cat_list='var'+'_'+var
cat_list = pd.get_dummies(hr[var], prefix=var)
hr1=hr.join(cat_list)
hr=hr1
The actual categorical variable needs to be removed once the dummy variables have been created.
Column names after creating dummy variables for categorical variables:
hr.drop(hr.columns[[8, 9]], axis=1, inplace=True)
hr.columns.values
array(['satisfaction_level', 'last_evaluation', 'number_project',
'average_montly_hours', 'time_spend_company', 'Work_accident',
'left', 'promotion_last_5years', 'department_RandD',
'department_accounting', 'department_hr', 'department_management',
'department_marketing', 'department_product_mng',
'department_sales', 'department_technical', 'salary_high',
'salary_low', 'salary_medium'], dtype=object)
The outcome variable is “left”, and all the other variables are predictors.
hr_vars=hr.columns.values.tolist() y=['left'] X=[i for i in hr_vars if i not in y]
Feature Selection
The Recursive Feature Elimination (RFE) works by recursively removing variables and building a model on those variables that remain. It uses the model accuracy to identify which variables (and combination of variables) contribute the most to predicting the target attribute.
Let’s use feature selection to help us decide which variables are significant that can predict employee turnover with great accuracy. There are total 18 columns in X, how about select 10?
from sklearn.feature_selection import RFE from sklearn.linear_model import LogisticRegression model = LogisticRegression() rfe = RFE(model, 10) rfe = rfe.fit(hr[X], hr[y]) print(rfe.support_) print(rfe.ranking_) [ True True False False True True True True False True True False False False False True True False] [1 1 3 9 1 1 1 1 5 1 1 6 8 7 4 1 1 2]
You can see that RFE chose the 10 variables for us, which are marked True in the support_ array and marked with a choice “1” in the ranking_array. They are:
[‘satisfaction_level’, ‘last_evaluation’, ‘time_spend_company’, ‘Work_accident’,
‘promotion_last_5years’, ‘department_RandD’, ‘department_hr’, ‘department_management’,
‘salary_high’, ‘salary_low’]
cols=['satisfaction_level', 'last_evaluation', 'time_spend_company', 'Work_accident', 'promotion_last_5years',
'department_RandD', 'department_hr', 'department_management', 'salary_high', 'salary_low']
X=hr[cols]
y=hr['left']
Logistic Regression Model
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
logreg = LogisticRegression()
logreg.fit(X_train, y_train)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
from sklearn.metrics import accuracy_score
print('Logistic regression accuracy: {:.3f}'.format(accuracy_score(y_test, logreg.predict(X_test))))
Logistic regression accuracy: 0.771
Random Forest
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier()
rf.fit(X_train, y_train)
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_split=1e-07, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
n_estimators=10, n_jobs=1, oob_score=False, random_state=None,
verbose=0, warm_start=False)
print('Random Forest Accuracy: {:.3f}'.format(accuracy_score(y_test, rf.predict(X_test))))
Random Forest Accuracy: 0.978
Support Vector Machine
from sklearn.svm import SVC svc = SVC() svc.fit(X_train, y_train) SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape=None, degree=3, gamma='auto', kernel='rbf', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False)
print('Support vector machine accuracy: {:.3f}'.format(accuracy_score(y_test, svc.predict(X_test))))
Support vector machine accuracy: 0.909
The winner is … Random forest, right?
Cross Validation
Cross validation attempts to avoid overfitting while still producing a prediction for each observation dataset. We are using 10-fold Cross-Validation to train our Random Forest model.
from sklearn import model_selection
from sklearn.model_selection import cross_val_score
kfold = model_selection.KFold(n_splits=10, random_state=7)
modelCV = RandomForestClassifier()
scoring = 'accuracy'
results = model_selection.cross_val_score(modelCV, X_train, y_train, cv=kfold, scoring=scoring)
print("10-fold cross validation average accuracy: %.3f" % (results.mean()))
10-fold cross validation average accuracy: 0.977
The average accuracy remains very close to the Random Forest model accuracy; hence, we can conclude that the model generalizes well.
Precision and recall
We construct confusion matrix to visualize predictions made by a classifier and evaluate the accuracy of a classification.
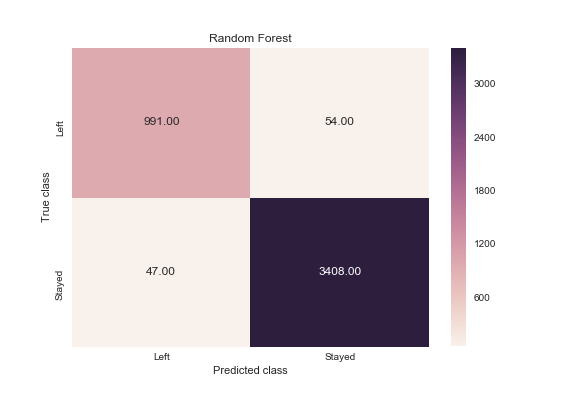
Random Forest
from sklearn.metrics import classification_report
print(classification_report(y_test, rf.predict(X_test)))
precision recall f1-score support
0 0.99 0.98 0.99 3462
1 0.95 0.95 0.95 1038
avg / total 0.98 0.98 0.98 4500
y_pred = rf.predict(X_test)
from sklearn.metrics import confusion_matrix
import seaborn as sns
forest_cm = metrics.confusion_matrix(y_pred, y_test, [1,0])
sns.heatmap(forest_cm, annot=True, fmt='.2f',xticklabels = ["Left", "Stayed"] , yticklabels = ["Left", "Stayed"] )
plt.ylabel('True class')
plt.xlabel('Predicted class')
plt.title('Random Forest')
plt.savefig('random_forest')
Gives this plot:
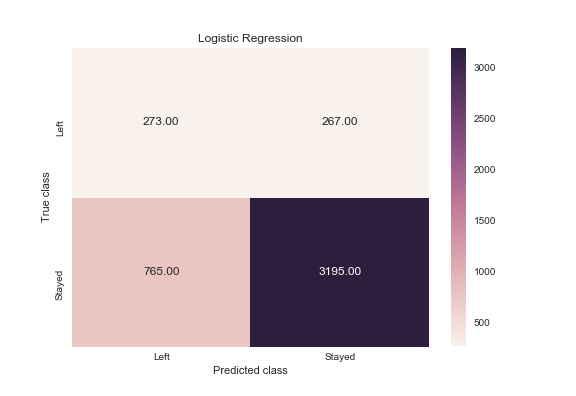
Logistic Regression
print(classification_report(y_test, logreg.predict(X_test)))
precision recall f1-score support
0 0.81 0.92 0.86 3462
1 0.51 0.26 0.35 1038
avg / total 0.74 0.77 0.74 4500
logreg_y_pred = logreg.predict(X_test)
logreg_cm = metrics.confusion_matrix(logreg_y_pred, y_test, [1,0])
sns.heatmap(logreg_cm, annot=True, fmt='.2f',xticklabels = ["Left", "Stayed"] , yticklabels = ["Left", "Stayed"] )
plt.ylabel('True class')
plt.xlabel('Predicted class')
plt.title('Logistic Regression')
plt.savefig('logistic_regression')
Gives this plot:
Support Vector Machine
print(classification_report(y_test, svc.predict(X_test)))
precision recall f1-score support
0 0.96 0.92 0.94 3462
1 0.77 0.86 0.81 1038
avg / total 0.91 0.91 0.91 4500
svc_y_pred = svc.predict(X_test)
svc_cm = metrics.confusion_matrix(svc_y_pred, y_test, [1,0])
sns.heatmap(svc_cm, annot=True, fmt='.2f',xticklabels = ["Left", "Stayed"] , yticklabels = ["Left", "Stayed"] )
plt.ylabel('True class')
plt.xlabel('Predicted class')
plt.title('Support Vector Machine')
plt.savefig('support_vector_machine')
Gives this plot:
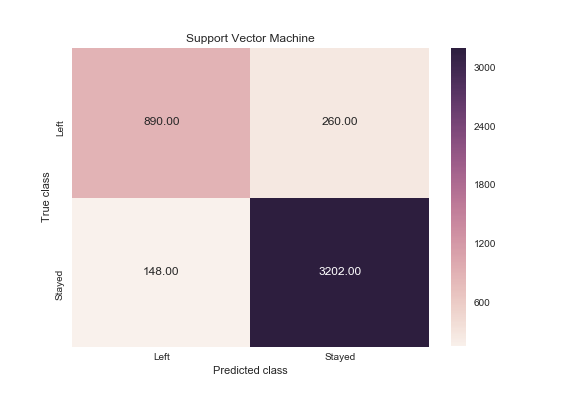
When an employee left, how often does my classifier predict that correctly? This measurement is called “recall” and a quick look at these diagrams can demonstrate that random forest is clearly best for this criteria. Out of all the turnover cases, random forest correctly retrieved 991 out of 1038. This translates to a turnover “recall” of about 95% (991/1038), far better than logistic regression (26%) or support vector machines (85%).
When a classifier predicts an employee will leave, how often does that employee actually leave? This measurement is called “precision”. Random forest again outperforms the other two at about 95% precision (991 out of 1045) with logistic regression at about 51% (273 out of 540), and support vector machine at about 77% (890 out of 1150).
The ROC Curve
from sklearn.metrics import roc_auc_score
from sklearn.metrics import roc_curve
logit_roc_auc = roc_auc_score(y_test, logreg.predict(X_test))
fpr, tpr, thresholds = roc_curve(y_test, logreg.predict_proba(X_test)[:,1])
rf_roc_auc = roc_auc_score(y_test, rf.predict(X_test))
rf_fpr, rf_tpr, rf_thresholds = roc_curve(y_test, rf.predict_proba(X_test)[:,1])
plt.figure()
plt.plot(fpr, tpr, label='Logistic Regression (area = %0.2f)' % logit_roc_auc)
plt.plot(rf_fpr, rf_tpr, label='Random Forest (area = %0.2f)' % rf_roc_auc)
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic')
plt.legend(loc="lower right")
plt.savefig('ROC')
plt.show()
Gives this plot:

The receiver operating characteristic (ROC) curve is another common tool used with binary classifiers. The dotted line represents the ROC curve of a purely random classifier; a good classifier stays as far away from that line as possible (toward the top-left corner).
Feature Importance for Random Forest Model
feature_labels = np.array(['satisfaction_level', 'last_evaluation', 'time_spend_company', 'Work_accident', 'promotion_last_5years',
'department_RandD', 'department_hr', 'department_management', 'salary_high', 'salary_low'])
importance = rf.feature_importances_
feature_indexes_by_importance = importance.argsort()
for index in feature_indexes_by_importance:
print('{}-{:.2f}%'.format(feature_labels[index], (importance[index] *100.0)))
promotion_last_5years-0.20%
department_management-0.22%
department_hr-0.29%
department_RandD-0.34%
salary_high-0.55%
salary_low-1.35%
Work_accident-1.46%
last_evaluation-19.19%
time_spend_company-25.73%
satisfaction_level-50.65%
According to our Random Forest model, the above shows the most important features which influence whether to leave the company, in ascending order.
Summary
This brings us to the end of the post. Remember that we can’t have an algorithm for everyone. Employee turnover analysis can help guide decisions, but not make them. Use analytics carefully to avoid legal issues and mistrust from employees, and use them in conjunction with employee feedback, to make the best decisions possible.
Source code that created this post can be found here. I would be pleased to receive feedback or questions on any of the above.
Hi, Susan, one question about the following code:
cat_vars=[‘department’,’salary’]
for var in cat_vars:
cat_list=’var’+’_’+var
cat_list = pd.get_dummies(hr[var], prefix=var)
hr1=hr.join(cat_list)
hr=hr1
You can use factorize to get the same result:
hr[‘department’] = pd.factorize(hr[‘department’])[0]
hr[‘salary’] = pd.factorize(hr[‘salary’])[0]
Thanks.
Dennis
Thank you for sharing Dennis
is there a way to identify who falls into each predicted and actual category on the Random Forest model in the test set.
https://uploads.disquscdn.com/images/666b2c547fa52ff52a234911a52e0558c241fa0c1e2bcdb3d0811ed54124188e.png