There was a time when Web scraping was quite a difficult task requiring knowledge of XML Tree parsing and HTTP Requests. But with the likes of libraries like beautifulsoup (for Python) and rvest (for R), Web scraping has become a toy for any beginner to play with.
This post aims to explain how insanely simple it is to build a scraper in R using rvest and the site we have decided to scrape content from is Hacker News Front Page.
Package Installation and Loading
rvest can be installed from CRAN and loaded into R like below:
install.packages('rvest')
library(rvest)
read_html() function of rvest can be used to extract the html content of the url given as the arguemnt for read_html function.
content <- read_html('https://news.ycombinator.com/')
For this above read_html() to work without any concern, Please make sure you are not behind any organization firewall and if so, configure your RStudio with a proxy to bypass the firewall otherwise you might face connection timed out error.
Below is the screenshot of HN front page layout (with key elements highlighted):
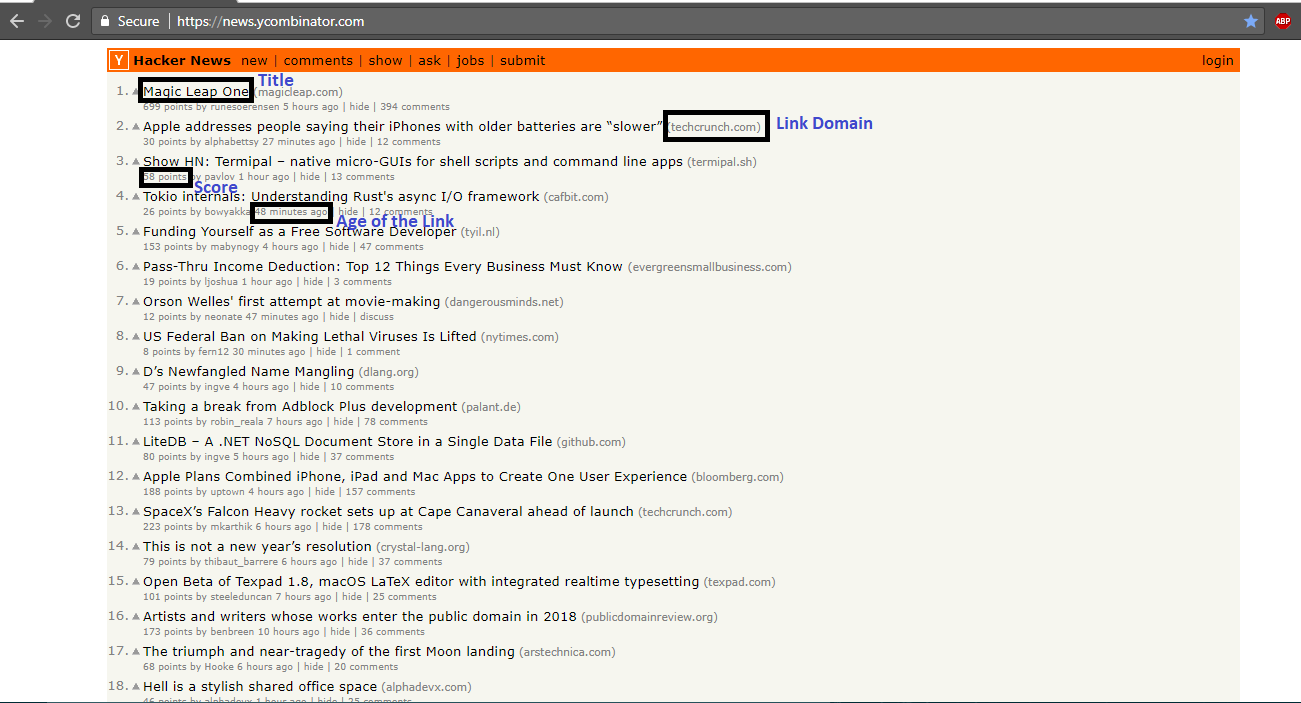
Now, with the html content of the Hacker News front page loaded into the R object content, Let us extract the data that we need – starting from the Title. The most important aspect of making any web scraping assignment successful is to identify the right css selector or xpath values of the html elements whose values are supposed to be scraped and the easiest way to get the right element value is to use the inspect tool in Developer Tools of any browser.
Here’s the screenshot of the css selector value highlighted by Chrome Inspect Tool when hovered over Title of the links present in Hacker News Frontpage.
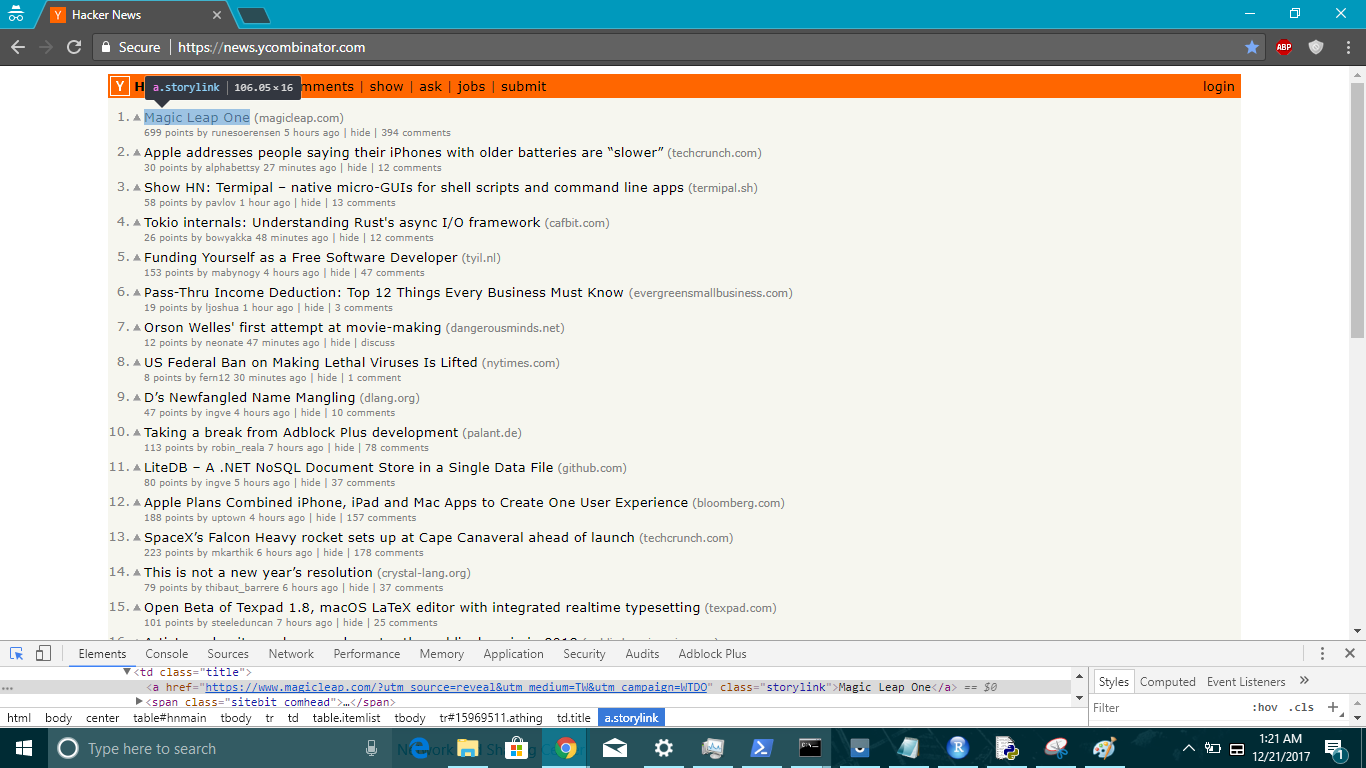
title <- content %>% html_nodes('a.storylink') %>% html_text()
title
[1] "Magic Leap One"
[2] "Show HN: Termipal – native micro-GUIs for shell scripts and command line apps"
[3] "Tokio internals: Understanding Rust's async I/O framework"
[4] "Funding Yourself as a Free Software Developer"
[5] "US Federal Ban on Making Lethal Viruses Is Lifted"
[6] "Pass-Thru Income Deduction"
[7] "Orson Welles' first attempt at movie-making"
[8] "D’s Newfangled Name Mangling"
[9] "Apple Plans Combined iPhone, iPad and Mac Apps to Create One User Experience"
[10] "LiteDB – A .NET NoSQL Document Store in a Single Data File"
[11] "Taking a break from Adblock Plus development"
[12] "SpaceX’s Falcon Heavy rocket sets up at Cape Canaveral ahead of launch"
[13] "This is not a new year’s resolution"
[14] "Artists and writers whose works enter the public domain in 2018"
[15] "Open Beta of Texpad 1.8, macOS LaTeX editor with integrated realtime typesetting"
[16] "The triumph and near-tragedy of the first Moon landing"
[17] "Retrotechnology – PC desktop screenshots from 1983-2005"
[18] "Google Maps' Moat"
[19] "Regex Parser in C Using Continuation Passing"
[20] "AT&T giving $1000 bonus to all its employees because of tax reform"
[21] "How a PR Agency Stole Our Kickstarter Money"
[22] "Google Hangouts now on Firefox without plugins via WebRTC"
[23] "Ubuntu 17.10 corrupting BIOS of many Lenovo laptop models"
[24] "I Know What You Download on BitTorrent"
[25] "Carrie Fisher’s Private Philosophy Coach"
[26] "Show HN: Library of API collections for Postman"
[27] "Uber is officially a cab firm, says European court"
[28] "The end of the Iceweasel Age (2016)"
[29] "Google will turn on native ad-blocking in Chrome on February 15"
[30] "Bitcoin Cash deals frozen as insider trading is probed"
Since rvest package supports pipe %>% operator, content (the R object containing the content of the html page read with read_html) can be piped with html_nodes() that takes css selector or xpath as its arugment and then extract respective xml tree (or html node value) whose text value could be extracted with html_text() function. The beauty of rvest is that it abstracts the entire xml parsing operation under the hood of functions like html_nodes() and html_text() making it easier for us to achieve our scraping goal with minimal code.
Like Title, The css selector value of other required elements of the web page can be identified with the Chrome Inspect tool and passed as an argument to html_nodes() function and respective values can be extracted and stored in R objects.
link_domain <- content %>% html_nodes('span.sitestr') %>% html_text()
score <- content %>% html_nodes('span.score') %>% html_text()
age <- content %>% html_nodes('span.age') %>% html_text()
With all the essential pieces of information extracted from the page, an R data frame can be made with the extracted elements to put the extracted data into a structured format.
df <- data.frame(title = title, link_domain = link_domain, score = score, age = age)
Below is the screenshot of the final dataframe in RStudio viewer:
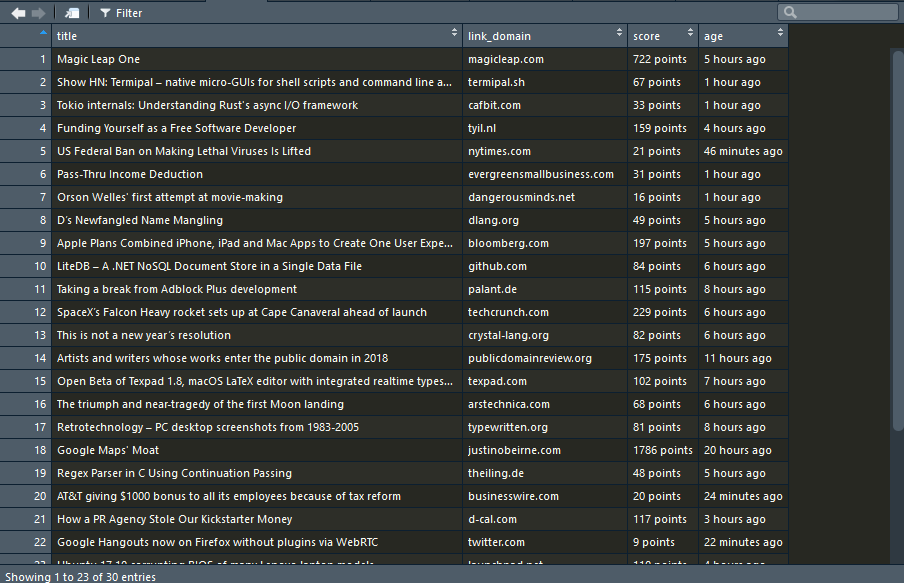
Thus in just 8 lines of code, We have successfully built a Hacker News Scraper in R using rvest package and this scraper could be for a variety of purposes like News Reader, Summarizer, Text Analytics and much more. While a lot more things could be done with rvest, this post is kept simple to explain how easily a web scraper could be built with rvest. The code used here is available on my github.
Whole of bootstrap.min.js is minified written on one line. But a very long one 🙂
Nice work. Can you remove the extra characters at the end of the content assignment that causes read_html to fail?
Thanks @rick_pack:disqus .That’s a nice catch. It’s a formatting error and fixed the code.