Missing Values in the dataset is one heck of a problem before we could get into Modelling. A lot of machine learning algorithms demand those missing values be imputed before proceeding further.
The popular (computationally least expensive) way that a lot of Data scientists try is to use mean / median / mode or if it’s a Time Series, then lead or lag record.
There must be a better way — that’s also easier to do — which is what the widely preferred KNN-based Missing Value Imputation.
scikit-learn‘s v0.22 natively supports KNN Imputer — which is now officially the easiest + best (computationally least expensive) way of Imputing Missing Value. It’s a 3-step process to impute/fill NaN (Missing Values). This post is a very short tutorial of explaining how to impute missing values using KNNImputer
Make sure you update your scikit-learn
pip3 install -U scikit-learn
1. Load KNNImputer
from sklearn.impute import KNNImputer
How does it work?
According scikit-learn docs:
Each sample’s missing values are imputed using the mean value from n_neighbors nearest neighbors found in the training set. Two samples are close if the features that neither is missing are close. By default, a euclidean distance metric that supports missing values, nan_euclidean_distances, is used to find the nearest neighbors.
Creating Dataframe with Missing Values
import numpy as np
import pandas as pd
dict = {'First':[100, 90, np.nan, 95],
'Second': [30, 45, 56, np.nan],
'Third':[np.nan, 40, 80, 98]}
# creating a dataframe from list
df = pd.DataFrame(dict)
Gives this:
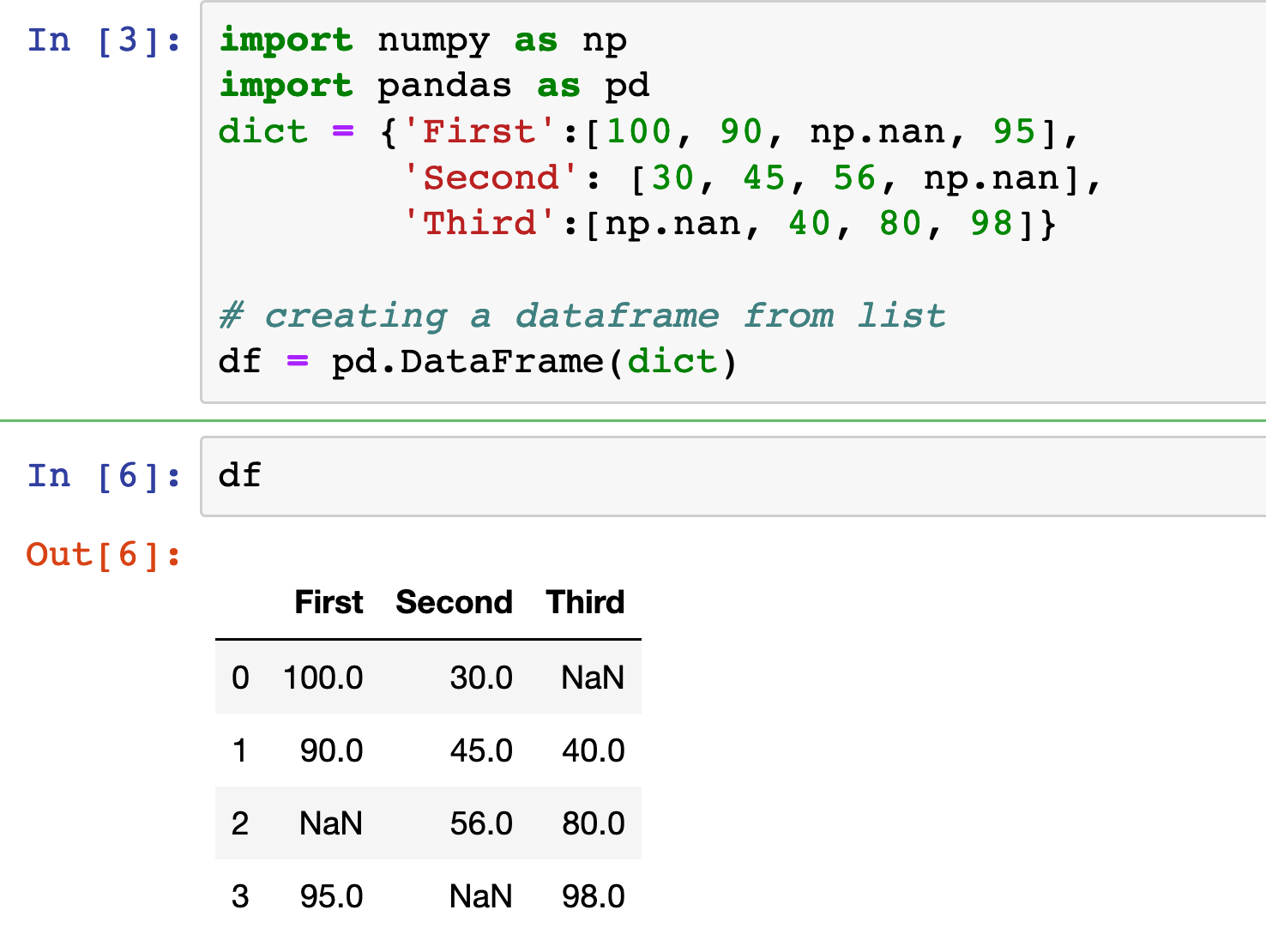
At this point, You’ve got the dataframe df with missing values.
2. Initialize KNNImputer
You can define your own n_neighbors value (as its typical of KNN algorithm).
imputer = KNNImputer(n_neighbors=2)
3. Impute/Fill Missing Values
df_filled = imputer.fit_transform(df)
Display the filled-in data
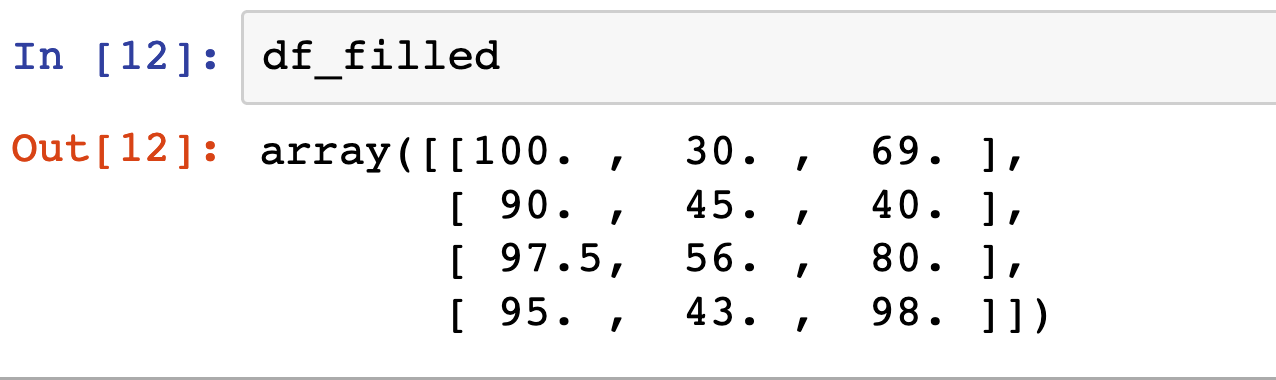
Conclusion
As you can see above, that’s the entire missing value imputation process is. It’s as simple as just using mean or median but more effective and accurate than using a simple average. Thanks to the new native support in scikit-learn, This imputation fit well in our pre-processing pipeline.