One of the biggest problems in Business to carry out any analysis is the availability of Data. That is where in many cases, Web Scraping comes very handy in creating that data that’s required. Consider the following case: To perform text analysis on Textual Data collected in a Telecom Company as part of Customer Feedback or Reviews, primarily requires a dictionary of Telecom Keywords. But such a dictionary is hard to find out-of-box. Hence as an Analyst, the most obvious thing to do when such dictionary doesn’t exist is to build one. Hence this article aims to help beginners get started with web scraping with rvest in R and at the same time, building a Telecom Dictionary by the end of this exercise.
Disclaimer
Web Scraping is not allowed by some websites. Kindly check the site’s Terms of Service before Scraping. This post is only for Educational-purpose.
A simple Google search for Telecom Glossary results in this URL:
Atis.org of which the required Telecom Dictionary could be built.
Let us start by loading the required libraries:
#load rvest and stringr library library(rvest) library(stringr) library(dplyr)
rvest is a web scraping library in R that makes it easier to write common scraping tasks (to scrape useful information from web pages) without getting our head into xml parsing. rvest can be downloaded from CRAN and the development version is also available on Github.
It could be seen in the above-mentioned URL that the Glossary words are listed alphabetically from A to Z with a separate link / URL for every (starting) letter. Clicking ‘A’ takes us to this link: atis.org that lists all the keywords with starting letter ‘A’. If you closely look at the URL, the code that’d be written for one letter (here in our case, ‘A’) could be easily replicated for other letters since ‘A’ is part of the URL which will be the only change for the link of other Alphabets.
Let us assign this URL to an R object url which could be passed on as the paramater to rvest’s read_html() function.
#url whose content to be scraped
url <- 'http://www.atis.org/glossary/definitionsList.aspx?find=A&kw=0'
#extracting the content of the given url
#url_content <- read_html('http://www.atis.org/glossary/definitionsList.aspx?find=A&kw=0')
url_content <- read_html(url)
read_html() parses the html page of the given url (as its parameter) and saves the result as an xml object.
To reiterate the objective, we are trying get the list of Telecom Keywords and as per the screenshot above, You could see that the Keywords are listed as Hyperlinks in the given url.
Hyperlinks in HTML is written in the following syntax:
<a href="https://www.google.com">Google</a>
Google is the Link Text Label that a browser would render and when clicked would take us to www.google.com. Hence it is evident that anchor tags in the page is what we are supposed to scrape/extract. But the issue with the current page is that, It’s not just the Keywords that are represented as Anchor Text (links) in the page but also there are a lot of other links (anchor tags) in the page. Hence to extract only the required information and filter out the irrelevant information, we need to find a pattern that helps us extract only the keywords links.
Have a look at this screenshot:
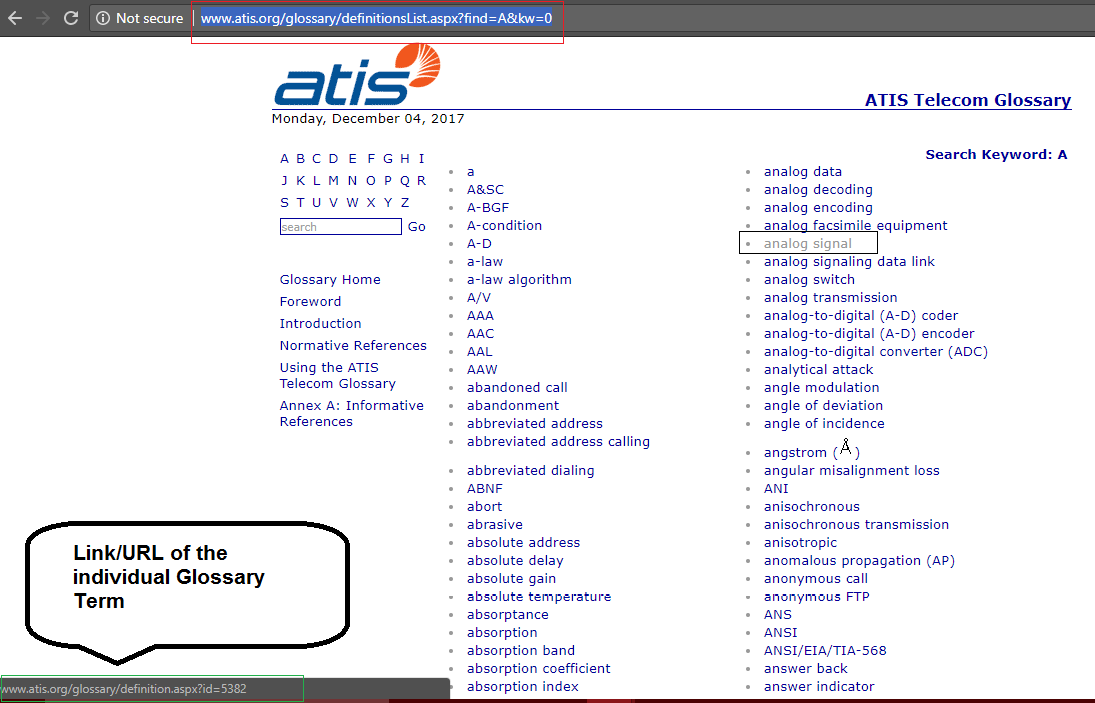
This screenshot shows that while the keywords are also represented as hyperlinks (Anchor Text), the differentiator is this ‘id’ element in the url. Only the links of the keywords have got this ‘id’ in the url and hence we can try extracting two information from the current page to get only the relevant information which in our case is – The Keywords: 1. Href value / Actual URL 2. Link Text.
#extracting all the links from the page
links <- url_content %>% html_nodes('a') %>% html_attr('href')
#extracting all thhe link text from the page
text <- url_content %>% html_nodes('a') %>% html_text()
With the example Hyperlink discussed earlier, the above code gives two informations.
www.google.com is saved in links and Google is saved in text.
With links and text as columns, Let us build a rough dictionary (that’s not yet cleaned/filtered).
#creating a new dictonary of links and text extracted above
rough_dict <- data.frame(links,text, stringsAsFactors = F)
head(rough_dict)
links text
1 http://www.atis.org
2 definitionsList.aspx?find=A&kw=0 A
3 definitionsList.aspx?find=B&kw=0 B
4 definitionsList.aspx?find=C&kw=0 C
5 definitionsList.aspx?find=D&kw=0 D
6 definitionsList.aspx?find=E&kw=0 E
As displayed above, rough_dict contains both signal (keywords) and noise (irrelevant links) and we have to filter the irrelevant out with the ‘id‘ pattern that we learnt earlier.
#filtering glossary terms leaving out irrelevant information
fair_dict <- rough_dict %>% filter(str_detect(links, 'id')) %>% select(text)
tail(fair_dict)
text
657 AN
658 axial propagation constant
659 analog component
660 axial ratio
661 analog computer
662 axial ray
And that’s how using str_detect() we can keep only links with ‘id’ in it and filter out the rest and building our fair_dict. As displayed in the above output, We have got 662 Keywords just for the letter ‘A’ and the same exercise could be repeated for the other letters available on the site. The only change that’s required is the url object. For example, Like this:
url <- 'http://www.atis.org/glossary/definitionsList.aspx?find=B&kw=0'
Note the ‘B’ in it and the same could be done for other available letters. This process could be further improved by making this scraping part a function and looping the function call over a character vector with all the available letters (which ideally is beyond the scope of this article’s objective and hence left out). The complete code used in this article is available on my Github.