The Data Science projects start with the collection of data. The data can be collected from the database, internet/online and offline mode. These days most of the information is available online and in order to extract that information Data Engineers/Data Scientists use Web Scraping. In this article we will learn about web scraping and how is it done in Python using openly available tools.
Introduction
Before we start learning and coding the web scrapper, Let’s try and understand, what is web scraping.
Wikipedia Definition: Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites. Web scraping software may access the World Wide Web directly using the Hypertext Transfer Protocol or through a web browser. While web scraping can be done manually by a software user, the term typically refers to automated processes implemented using a bot or web crawler. It is a form of copying, in which specific data is gathered and copied from the web, typically into a central local database or spreadsheet, for later retrieval or analysis.
For this article, we will extract the data for top restaurants in Bangalore(India) from Zomato website. The information will be accessed and read through HTML web pages. So, Let’s get started building a web scraper tool.
Website Content: Access and Scrap
In order to open a website on our browser, we type the website address and submit an HTTP request to access the webpage. This displays a webpage on the browser if the request is a success else we get an error. In order to access the Zomato website page, we would need to submit the request in the same way.
We have a few tools available which allow us to access the website within Python.
import requests from bs4 import BeautifulSoup
Before we use these libraries and their functions to access the website, let’s try and understand their usage.
Requests
It is designed to be used by humans to interact with the language. This means you don’t have to manually add query strings to URLs, or form-encode your POST data. Requests will allow you to send HTTP/1.1 requests using Python. With it, you can add content like headers, form data, multipart files, and parameters via simple Python libraries. It also allows you to access the response data of Python in the same way.
BS4 – BeautifulSoup
Beautiful Soup is a Python library for pulling data out of HTML and XML files. It works with your favorite parser to provide idiomatic ways of navigating, searching and modifying the parse tree. It commonly saves programmers hours or days of work.
Now that we know what these tools do, we can now try accessing the Zomato website.
#Used headers/agent because the request was timed out and asking for an agent.
#Using following code we can fake the agent.
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'}
response = requests.get("https://www.zomato.com/bangalore/top-restaurants",headers=headers)
Let’s try reading the content of the website as now we have successfully established the connection.
content = response.content soup = BeautifulSoup(content,"html.parser")
The above code will first dump the content retrieve after accessing the website. The dumped content then will be passed to the BeautifulSoup function in order to get only the data with HTML/valid website tags that were used to develop the website. Here is the snapshot of the content formatted by BeautifulSoup.
Top restaurants: Format the data
We now have the data for a Top restaurant on Zomato, dumped into a variable. But is it in a readable format? Maybe for a computer scientist but not for all the people. Let’s try to format the scraped data.
For this particular exercise, we are interested in extracting Restaurant’s Name, Restaurant’s Address and Type of Cuisine. In order to start looking for these details, we would need to find the HTML tags which store this information.
Take a pause and look at the BeautifulSoup content above or you can use inspect on your Chrome Web Browser, you will be able to see which tag keeps the collection of top restaurant and other tags which has further details.
top_rest = soup.find_all("div",attrs={"class": "bb0 collections-grid col-l-16"})
list_tr = top_rest[0].find_all("div",attrs={"class": "col-s-8 col-l-1by3"})
The above code will try to find all HTML div tags containing class equals to “col-s-8 col-l-1by3” and will return the collection/list of restaurants data. In order to extract the further information, we will need to access the list elements i.e. one restaurant information one by one using a loop.
list_rest =[]
for tr in list_tr:
dataframe ={}
dataframe["rest_name"] = (tr.find("div",attrs={"class": "res_title zblack bold nowrap"})).text.replace('\n', ' ')
dataframe["rest_address"] = (tr.find("div",attrs={"class": "nowrap grey-text fontsize5 ttupper"})).text.replace('\n', ' ')
dataframe["cuisine_type"] = (tr.find("div",attrs={"class":"nowrap grey-text"})).text.replace('\n', ' ')
list_rest.append(dataframe)
list_rest
In the above code, tr will contain the different information about the restaurant like – Name, address,
Cuisine, prices, menu, reviews etc. Each information is stored in different tags and the tags can be found after looking at the tr(each element’s data).
Before finding the tags in the HTML dump, we should try and check how does the list of the restaurant actually look like on the website.
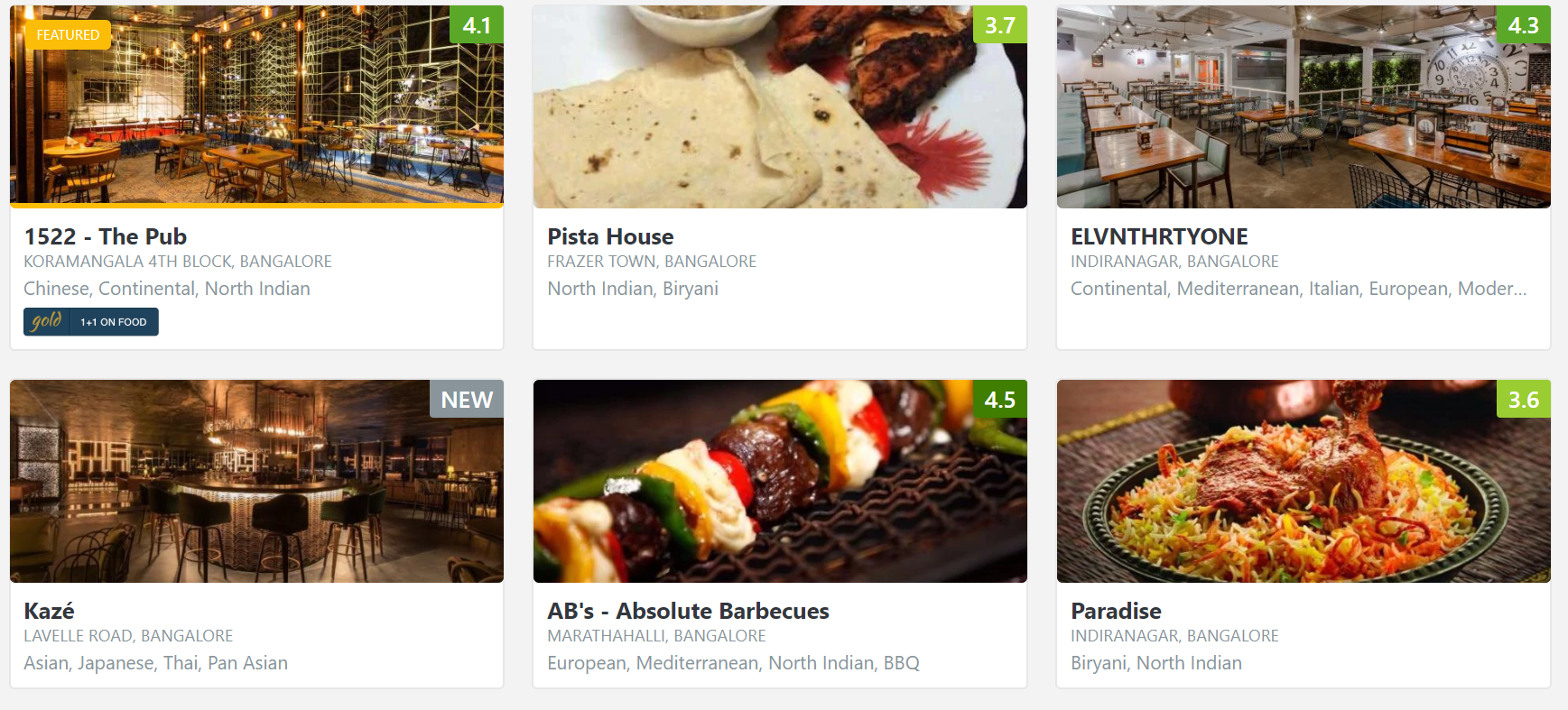
From above image, you can see that the information we want to extract for this exercise is displaying in different fonts or formats. Going back to the HTML dump/content we found that information is stored inside a div tag with classes defined as the type of fonts used or the used formats.
We have defined a DataFrame to collect the required information. Restaurant Name is stored underclass – res_title zblack bold nowrap, Restaurant Address is stored underclass – nowrap grey-text fontsize5 ttupper and Cuisine type is stored under class – nowrap grey-text.
We will access this information one by one and store them into different DataFrame columns. We will also have to use few String function here because the HTML data uses \n to separate the data and cannot be stored into the DataFrame. So, to avoid any errors – we can replace \n with ”(space).
The output of above code will look something like this –

Save Data in Human Readable format
Thinking of giving above data to someone who does not know Python? Will they be able to read the data? Maybe not. We will save the data frame data to CSV format which is easily readable.
import pandas
df = pandas.DataFrame(list_rest)
df.to_csv("zomato_res.csv",index=False)
The above code will create a CSV file named zomato_res.
Summary
Throughout this post, we saw how we can use request to access any website from a python code and use BeautifulSoup to extract the HTML content. After extracting the content we formatted it using data frame and later saved the data in CSV file. There was more information that can be retrieved from the website but this post was to find a restaurant, their address, and cuisine. Though the similar process can be used to scrap the data from other websites too.
References
- GitHub Repo
- Motivation – Finding popular blog
- Web Scraping
- BeautifulSoup and HTTP Request
hi can anyone help me with scraping data from ministry of education website school name all over India in table format which have attributes like school name location e-mail address these information
Hi.. I was able to use this post as a guide. I eventually got here
top_rest = soup.find_all("div",attrs={"class": "sc-bblaLu dOXFUL"})list_tr = top_rest[0].find_all("div",attrs={"class": "sc-gTAwTn cKXlHE"})
I was getting this output error:
Other code is in place. Is there anything you can advise I do here?
Hi! can you help me in extracting all the zomato reviews with the reviewer name of a particular restaurant?
Sir how can we retrieve zomato restaurant all reviews.I tried but getting encode error because of comment,How to resolve it and also another question how to all reviews because it display through ajax.Please help me.
Is there a way to reach out to the author of this post?
is web scraping legitimate ?
That depends on the terms of the content you’re scraping and the copyright laws in your location. A single read is no different from a very attentive human who probably doesn’t have JavaScript enabled and isn’t particularly interested in random ads.