This is a continuation of my previous article, where I gave a basic overview of how to construct heatmaps in R. Here, I will show you how to use R packages to build a heatmap on top of the map of Chicago to see which areas have the most amount of crime. We will require two packages for the mapping, namely maps, and ggmap. We will also use two more packages, dplyr, and tidyr.
I will be using the Motor Vehicle Theft Data from Chicago, which can be obtained from the City of Chicago Data Portal.
The first part of the code is the same as my previous article.
The second part of the code will contain the following steps:
- Removing empty locations. For some thefts, the location is not recorded, and the field is left blank. This caused problems for me later on, so I decided to remove all such locations. At the time of writing, empty locations made up about 2500 entries of the total 278000 entries.
- Splitting the location column into latitude and longitude. The location column consists of data in the form (x, y) and is of the character class. We want x and y to be in separate columns and be of the numeric class. We will use the dplyr and tidyr libraries for this.
- Get the map of Chicago. We will use the ggmap library for this
- Plotting the location heatmap.
Here is the code:
## Removing empty locations chicagoMVT$Location[chicagoMVT$Location == ''] <- NA chicagoMVT <- na.omit(chicagoMVT) Copy
We set all empty values to NA, and then change the original dataset so that it no longer contains the NA values.
## Splitting location into latitude and longitude
chicagoMVT <- chicagoMVT %>% extract(Location, c('Latitude', 'Longitude'), '\\(([^,]+), ([^)]+)\\)')
chicagoMVT$Longitude <- round(as.numeric(chicagoMVT$Longitude), 2)
chicagoMVT$Latitude <- round(as.numeric(chicagoMVT$Latitude), 2)
Copy
%>% is called the pipe operator. It is from the dplyr package. The above line of code is the same as writing
chicagoMVT <- extract(chicagoMVT, Location, c('Latitude', 'Longitude'), '\\(([^,]+), ([^)]+)\\)')
Copy
As we can see, the pipe operator is very helpful to pass output resulting from one operation to another. While it isn’t particularly useful here, it’s usefulness becomes apparent when you have to perform multiple operations, and don’t want to create a temporary variable for the result of each of the operations. I will do a short of tutorial and demonstration of dplyr in my next article.
The extract method is from the tidyr package, and I am using it to separate the Location column into Latitude and Longitude. The last parameter of the extract method is a Regular Expression or RegEx for short. I often have problems with RegEx, and this time was no different, and I’d like to thank StackOverflow user nongkrong for helping me with that.
Both dplyr and tidyr are great packages written by Hadly Wickham, the man who revolutionised R. I highly recommend that you check out his body of work and read his books.
Next, we will get the map of Chicago, so that we plot on top of it.
library(ggmap) chicago <- get_map(location = 'chicago', zoom = 11) Copy
If you would like to see the map, you can use this command:
ggmap(chicago) Copy
which will give the following map
Now we will create a data frame containing the coordinates of all the thefts.
locationCrimes <- as.data.frame(table(chicagoMVT$Longitude, chicagoMVT$Latitude))
names(locationCrimes) <- c('long', 'lat', 'Frequency')
locationCrimes$long <- as.numeric(as.character(locationCrimes$long))
locationCrimes$lat <- as.numeric(as.character(locationCrimes$lat))
locationCrimes <- subset(locationCrimes, Frequency > 0)
Copy
As we saw in the above map, the axes are named ‘long’ and ‘lat’, so we will use the same naming convention for our data frame. When we create the data frame, the latitude and longitude get converted to the factor class. To convert it back to numeric, we have to first convert them back to character, and then to numeric (otherwise it will give an error). Finally, we remove all data points where there were no crimes recorded. If you don’t do this, the resulting plot will have a lot of tiles plotted on the water, which we don’t want.
ggmap(chicago) + geom_tile(data = locationCrimes, aes(x = long, y = lat, alpha = Frequency),
fill = 'red') + theme(axis.title.y = element_blank(), axis.title.x = element_blank())
Copy
alpha = Frequency will set how transparent/opaque each tile is, based on the frequency of crimes in that particular area.
theme(axis.title.y = element_blank(), axis.title.x = element_blank()) will remove the titles for the axes.
This will generate the following plot:
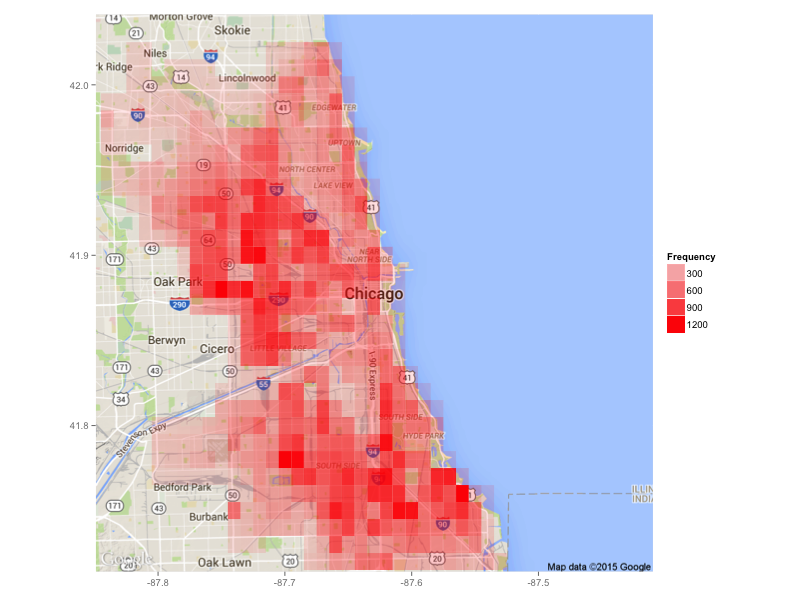
The plot gives us a pretty good idea of which areas are the most prone to thefts, and thus should be avoided. The police are using advanced crime prediction algorithms to predict where crimes will happen, and prevent them before they occur. Here is a great article by MIT Technology Review on the topic.
The full repo can be found on GitHub.
That’s it for now! I hope you enjoyed the article, and found it helpful. Feel free to leave a comment if you have any questions or contact me on Twitter!
Note: I learnt this technique in The Analytics Edge course offered by MIT on edX. It is a great course and I highly recommend that you take it if you are interested in Data Science!