Web Scraping, which is an essential part of Getting Data, used to be a very straightforward process just by locating the html content with xpath or css selector and extracting the data until Web developers started inserting Javascript-rendered content in the web page. Hence a css selector or an xpath pointing to a browser-generated / javascript-rendered front-end content does not contain html, instead a javascript snippet in the code source. This makes any conventional html scrapper incomplete in the stack since a javascript engine is required to run the extracted javascript code (actual scraped content from the web page) and output the desired result.
This above statement could be slightly confusing at first sight. Let me try to explain this with an example.
When you open this link: https://food.list.co.uk/place/22191-brewhemia-edinburgh/, You’d be presented with the details like Telephone, Email Id, Website of the listed place as in the below screenshot:

While it is easy to scrape some details like Telephone and Website from the above link, Email ID is the trickiest one – as the site’s developers have decided to make it js(javascript)-rendered content, possibly to fight spam or perhaps to discourage scraping.
Even the browser’s developer console does not reveal it is the trickiest, as it shows the rendered content (the actual Email ID) when we try to inspect that particular element (Refer the screenshot below):
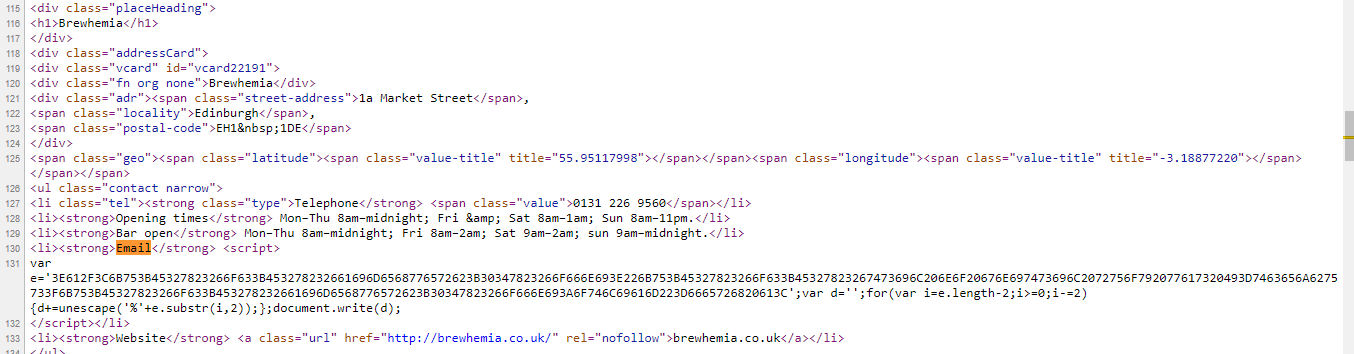
But when we try scraping all we will be left with is a small snippet of javascript code, which is also revealed by the page source. (Refer the screenshot below)
This is when we realize, the go-to web scraping r-package rvest might not be able to help and a little bit of Google search would guide to use Selenium or Phantomjs (headless chrome). Behold, there might be something in R, precisely an R package, to help us. The package name is V8 which is an R interface to Google’s open source JavaScript engine. This package helps us execute javascript code in R without leaving the current R session. Coupling this package with rvest, It is now possible to programmatically extract the email ID in that page with the below R code.
#Loading both the required libraries
library(rvest)
library(V8)
#URL with js-rendered content to be scraped
link <- 'https://food.list.co.uk/place/22191-brewhemia-edinburgh/'
#Read the html page content and extract all javascript codes that are inside a list
emailjs <- read_html(link) %>% html_nodes('li') %>% html_nodes('script') %>% html_text()
# Create a new v8 context
ct <- v8()
#parse the html content from the js output and print it as text
read_html(ct$eval(gsub('document.write','',emailjs))) %>%
html_text()
[email protected]
Thus we have used rvest to extract the javascript code snippet from the desired location (that is coded in place of email ID) and used V8 to execute the javascript snippet (with slight code formatting) and output the actual email (that is hidden behind the javascript code). The source code can be found on my Github.
Hello! Do is it possible to trigger a “dopostback” function with the V8 package? Would anyone have an example?
Thanks for sharing! even though i didn’t quite understand this line of code: “read_html(ct$eval(gsub(‘document.write’,”,emailjs))) %>% html_text()”
Especially the gsub(”document.write’,”,emailjs) part
it would be so nice of you if you could tell me what the “document.write” is
This is really nice, thanks!
Hey @colinfayme:disqus Thanks! Your proustr package is also very nice!
The code seems incomplete. “object ’emailjs’ not found”
Thanks for pointing out. Fixed it! Please check!
Thanks for pointing it. Fixed it. Please check.
Great topic! This looks much cleaner than using a headless chrome browser. I’m going to try it out.
Hi @raymondbuhr:disqus , Thanks! Headless chrome would still make sense in a lot of cases – especially event emulation but simple js compiling this helps!
Wow, thanks for the tip! Much better than the RSelenium method I’ve used in the past.
Thanks @disqus_yaytfKr5rX:disqus. Looking forward for your opinion after trying this out.