Wordle has been around for some time now and I think it’s not quite necessary to explain what it is and how to play it. (If I lost you there, please read more about it (and play) here). I’m not the best for wording games, thus I don’t find them quite entertaining. But, thinking of algorithmic ways to find puzzle solutions faster using R is! That’s why I started to think of random ideas regarding Wordle: for people who have played a lot, what’s their guessing word distribution look like? Are there better or worse words to start with? Are there significant more relevant letters that would be useful to guess your first try?
I’ve seen some people answer similar questions after I started thinking on the matter, especially on most frequent letters by position (post), and a way to play and replicate the game using R (post).
Keep in mind the “winner starting word” you find depends on:
1. the words you pick to evaluate as possible best words,
2. the words you are trying to predict and test toward,
3. the valid words randomly picked to guess, based on the set of seeds picked to select those words
Yet, it gives us a winner solution.
1. Install and load lares
Run install.packages("lares") and then, load it with library("lares"). No more packages needed from now on.
2. Select your starting point
Let’s pick some “good words” to see which ones are the best. I won’t get into details but I set a couple of rules based on letter by position frequency to set these initial words. There are 48 words that comply with these filters. I’m using some old Scrabble functions I previously developed for the library for this purpose.
some_words <- scrabble_words( language = "en", # for English words tiles = "ESAORILTNU", # 67% cumulative letters force_n = 5, # comply Wordle universe of 5 letter words force_start = "s", # 16% words start with S force_str = "e")$word # most frequent letter sort(toupper(some_words)) [1] "SAINE" "SALET" "SALUE" "SANER" "SAUTE" "SENOR" "SENTI" ...
We could sample some of them, manually pick those we like most, or simply use all if you’re patient enough to run the simulations:
best_words <- toupper(some_words)
Now, I picked 10 random words we are going to guess, starting from the “best words” we picked. The more we use, the better it’ll represent the universe of words (which is about 13K 5 letter words).
set.seed(2) # For reproducibility (same results)
test_words <- toupper(sample(wordle_dictionary("en"), 10)); test_words # Words to guess randomly picked
[1] "BOZOS" "RESET" "TROWS" "SALTS" "JIBES" "YIRKS" "DURST" "SITES" "PENGO" "GARRE"
Finally, how many different random picking scenarios we’d like to test on each combination of best words and test words:
seeds <- 20 # Number of different random picks to check distribution
So basically expect for 480 iterations in total if you use these same settings. For me, it took about 30 minutes using my personal computer.
print(length(best_words) * length(test_words), seeds)
3. Run simulations
Now that we already set our starting point, let’s run the simulations.
results <- temp <- NULL
tic("wordle_loop")
for (word in best_words) {
cat(sprintf("- Seed word: %s [%s/%s]\n", word, which(word == best_words), length(best_words)))
for (objective in test_words) {
cat(sprintf("Guess %s [%s/%s] <= %s simulations: ", objective, which(objective == test_words), length(test_words), seeds))
temp <- wordle_simulation(word, objective, seed = 1:seeds, print = FALSE, quiet = TRUE)
results[[word]][[objective]] <- temp
cat(signif(mean(sapply(temp, function(x) x$iters)), 4), "\n")
}
}
toc("wordle_loop")
- Seed word: SALUE [1/48]
Guess BOZOS [1/10] <= 20 simulations: 6.95
Guess RESET [2/10] <= 20 simulations: 5.5
Guess TROWS [3/10] <= 20 simulations: 6.4
Guess SALTS [4/10] <= 20 simulations: 4.7
Guess JIBES [5/10] <= 20 simulations: 7.05
Guess YIRKS [6/10] <= 20 simulations: 6.55
Guess DURST [7/10] <= 20 simulations: 5.05
Guess SITES [8/10] <= 20 simulations: 6.95
Guess PENGO [9/10] <= 20 simulations: 5.3
Guess GARRE [10/10] <= 20 simulations: 6.05
- Seed word: SILEN [2/48]
Guess BOZOS [1/10] <= 20 simulations: 6.45
...
4. Gather results and check winners
Let’s check the sorted results to see the best and worst words.
best_means <- lapply(results, function(a) sapply(a,function(x) mean(sapply(x, function(x) x$iters)))) sort(sapply(best_means, mean)) STIRE SOARE SNARE STARE STORE STALE STEAL SNORE 5.205 5.240 5.325 5.325 5.365 5.380 5.385 5.400 ...
hist(sapply(best_means, mean), breaks = 30)
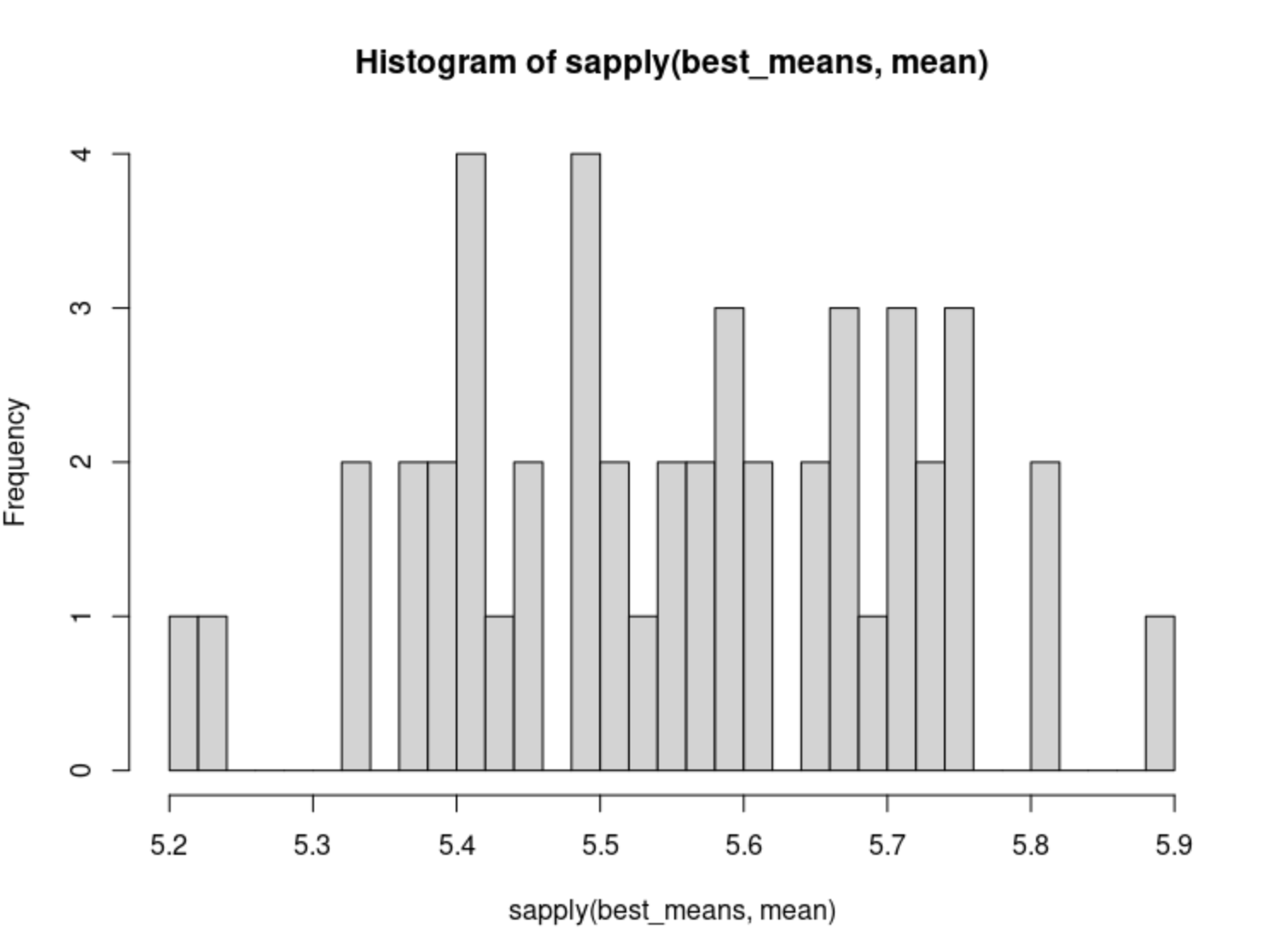
There’s a small range on these convergence means: (5.205, 5.890). That means that all these words are similarly good or bad compared with each other. But, notice we can actually easily pick or split the best from the worst words with this methodology.
To understand this point a bit more, let’s study a random benchmark: I picked 25 random words (not selected with the “best” words criteria) as my new best_words <- toupper(sample(some_words, 25)). Then, re-ran all the code with the same parameters and test words, for a total of 250 iterations, and got the following distribution. (Note: it took 18 minutes this time)
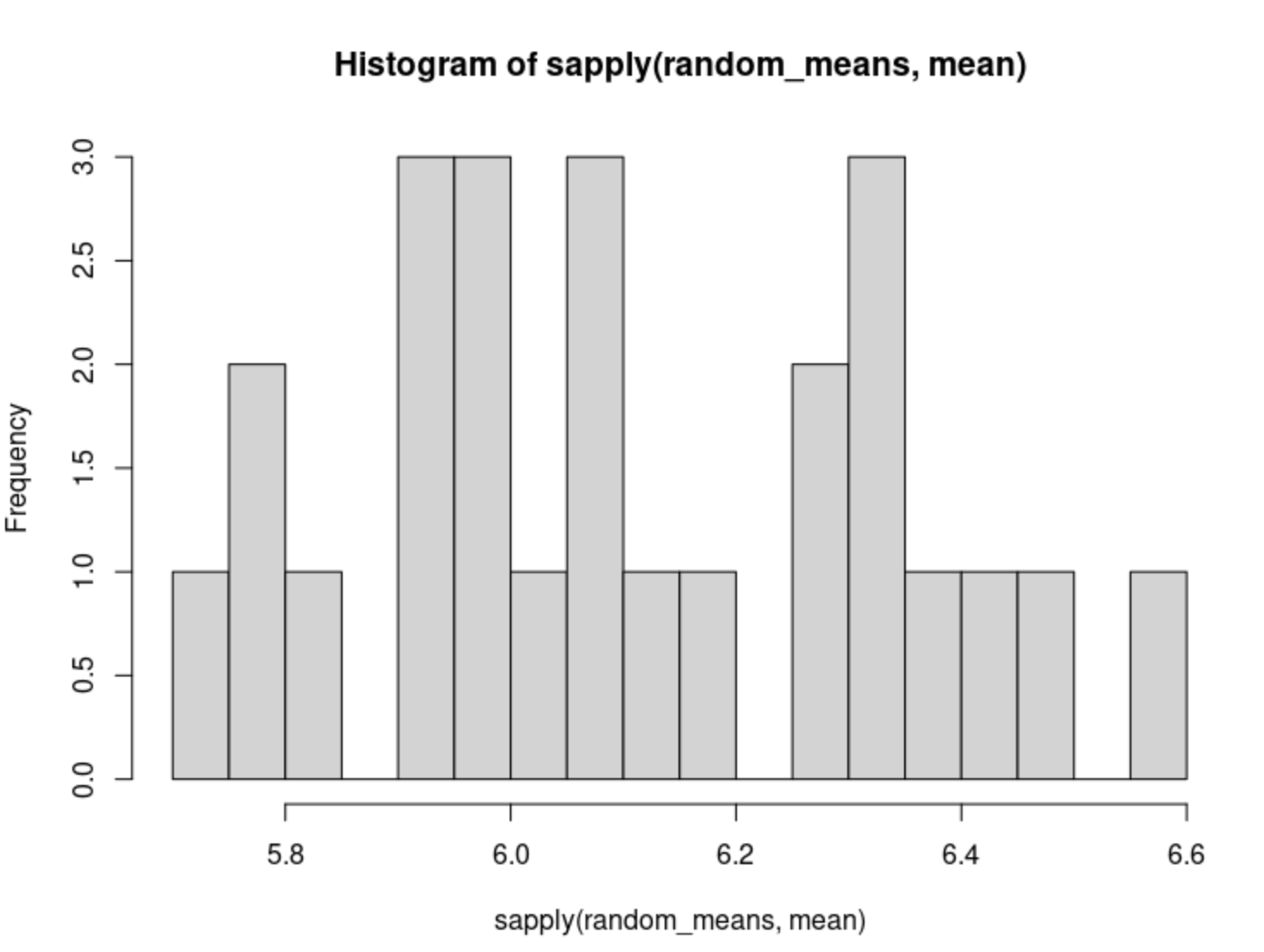
And theory confirmed. We did pick our first best words correctly given that the results given random words are really worse. Now the range covers a convergence mean of (5.700, 6.585). Notice that the best random words are not quite within the best words range but for a few lucky cases. And the best of the best words converge ~1.4 guesses before the worst of the random words. So we can actually do something about it and use better words to start our game!
Final comments, asks, and considerations
– There are other wordle_* functions in the package you can use as dictionary, to actually play, and to run simulations. Check out the nice colored results it prints. In the examples there is a small demo on how you can play with a random un-known word without limits.

– You probably won’t have a great difference on using one of the best picked words unless you play thousands of times: it’s more a matter of big numbers (and being smart on picking the right available words when guessing).
– You could try to re-run this analysis with a wider range of best words or test words to see if they can be improved. Note that the best words are the ones that converge sooner, thus lower iterations means.
– Expect to have these wordle_* functions updated in CRAN in a month or so (with nicer plots as well).
– Now, from the second input word onwards, it’s up to your picking skills. Feel free to check which words are left available using the scrabble_words() function.
Bonus benchmarks with different “best words” criteria
I ran one more experiment, using parallel calculations on 24 cores (which returned results in ~10min for 96 words and 40 iterations scenario), and got to the same conclusions as before, regardless of some outliers. FYI: “ESAORILT” are the most frequent letters, in order.
1) (all) 24 words containing E, starting with S, using any of “ESAORILT” letters
2) 96 good words containing E, using any of “ESAORILT” letters
3) 96 random words
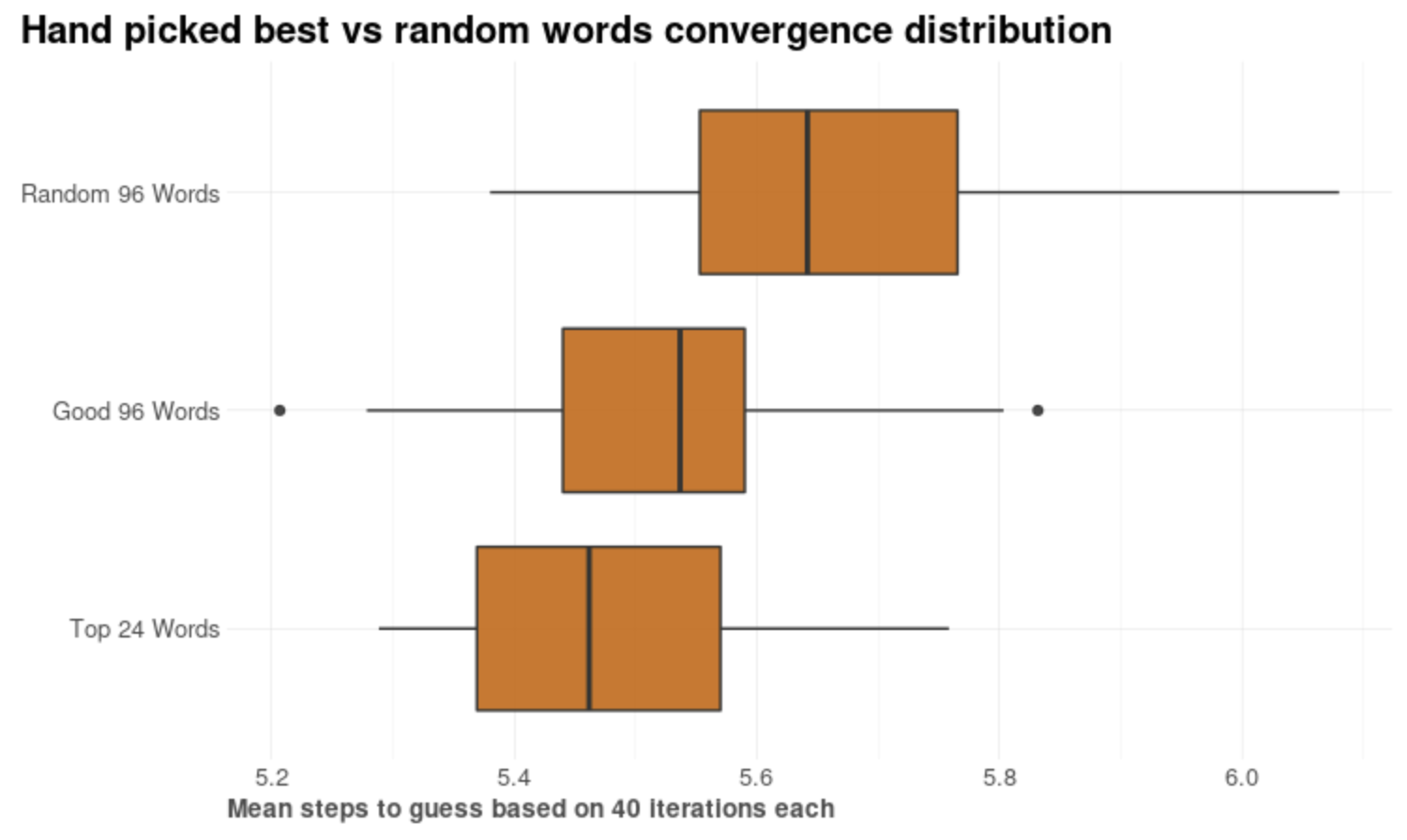
If you are wondering what those lower words are (remember the randomness factor), you’d get SOARE, ALERT, and RAILE. And the worst ones? LOGOI, KEVEL, and YAFFS.