This is a simple post to demonstrate how python can be used to do preliminary data analysis. I am using Python version 3.5.1 coming with Anaconda Python version 4.0 64 bit and my operating system is windows. To start with you can download Anaconda Python and install it in your machine. Once the installation is over, open the Anaconda Prompt which will appear in the start menu if you have installed in windows machine.
Your Anaconda Prompt will look like this:
Now type the following command in your Anaconda console prompt
pip install jupyter
Once the installation is done, type
jupyter notebook
This is how your notebook will look like this:
Next, I am going to use the following used cars dataset. The data set also comes from PACKT Publication for the book Machine Learning with R by Brett Lantz.
Once downloaded, you can read your data in the following way:
import os
import pandas as pd
os.chdir("")
df=pd.read_csv("usedcars.csv")
print(df.columns)
Index(['year', 'model', 'price', 'mileage', 'color', 'transmission'], dtype='object')
To see the first 5 rows of data table do the following:
print(df.iloc[1:5,:].values) [[2011 'SEL' 20995 10926 'Gray' 'AUTO'] [2011 'SEL' 19995 7351 'Silver' 'AUTO'] [2011 'SEL' 17809 11613 'Gray' 'AUTO'] [2012 'SE' 17500 8367 'White' 'AUTO']]
Now few of the features like color and transmission are not numerical and most of the ML algorithms will not be happy about this.
To get rid of this, we do the following
df1 = pd.get_dummies(df[['year', 'model', 'price', 'mileage', 'color', 'transmission'] ])
print(df1.columns)
Index(['year', 'price', 'mileage', 'model_SE', 'model_SEL', 'model_SES',
'color_Black', 'color_Blue', 'color_Gold', 'color_Gray', 'color_Green',
'color_Red', 'color_Silver', 'color_White', 'color_Yellow',
'transmission_AUTO', 'transmission_MANUAL'],
dtype='object')
So df1 is a new data frame which have all the columns of df but have additional columns with respect to each variety of color, model and transmission.
Check the first five values for df1:
print(df1.iloc[1:5,:].values)
[[ 2011 20995 10926 0 1 0 0 0 0 1 0 0
0 0 0 1 0]
[ 2011 19995 7351 0 1 0 0 0 0 0 0 0
1 0 0 1 0]
[ 2011 17809 11613 0 1 0 0 0 0 1 0 0
0 0 0 1 0]
[ 2012 17500 8367 1 0 0 0 0 0 0 0 0
0 1 0 1 0]]
Notice that all the previous categorical attributes are replaced with attributes that have Boolean values.
Now let us create some box plot with the price:
price =df1.iloc[1:,1].values print(price) [20995 19995 17809 17500 17495 17000 16995 16995 16995 16995 16992 16950 16950 16000 15999 15999 15995 15992 15992 15988 15980 15899 15889 15688 15500 15499 15499 15298 14999 14999 14995 14992 14992 14992 14990 14989 14906 14900 14893 14761 14699 14677 14549 14499 14495 14495 14480 14477 14355 14299 14275 14000 13999 13997 13995 13995 13995 13995 13992 13992 13992 13992 13991 13950 13950 13950 13895 13888 13845 13799 13742 13687 13663 13599 13584 13425 13384 13383 13350 12999 12998 12997 12995 12995 12995 12995 12995 12995 12995 12992 12990 12988 12849 12780 12777 12704 12595 12507 12500 12500 12280 11999 11992 11984 11980 11792 11754 11749 11495 11450 10995 10995 10995 10979 10955 10955 10836 10815 10770 10717 10000 9999 9999 9995 9995 9992 9651 9000 8999 8996 8800 8495 8494 8480 7999 7995 7995 7900 7488 6999 6995 6980 6980 6950 6200 5995 5980 4899 3800]
Now we will plot these prices as box plot:
import matplotlib.pyplot as plt plt.boxplot(price, 0, 'x') plt.show()
Here it is the plot:
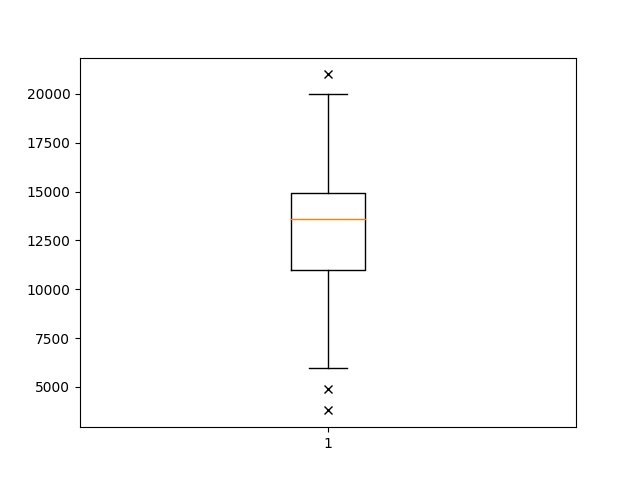
The symbol ‘x’ shows the outliers, the red line in the box marks the mean. You can try similar things for mileage as well.
Hope you find this very first post in Python useful.
df1 = pd.get_dummies(df[[‘year’, ‘model’, ‘price’, ‘mileage’, ‘color’, ‘transmission’] ])
print(df1.columns)
—————————————————————————
KeyError Traceback (most recent call last)
in ()
—-> 1 df1 = pd.get_dummies(df[[‘year’, ‘model’, ‘price’, ‘mileage’, ‘color’, ‘transmission’] ])
2 print(df1.columns)
C:UsersSAIAnaconda3libsite-packagespandascoreframe.py in __getitem__(self, key)
2054 if isinstance(key, (Series, np.ndarray, Index, list)):
2055 # either boolean or fancy integer index
-> 2056 return self._getitem_array(key)
2057 elif isinstance(key, DataFrame):
2058 return self._getitem_frame(key)
C:UsersSAIAnaconda3libsite-packagespandascoreframe.py in _getitem_array(self, key)
2098 return self.take(indexer, axis=0, convert=False)
2099 else:
-> 2100 indexer = self.loc._convert_to_indexer(key, axis=1)
2101 return self.take(indexer, axis=1, convert=True)
2102
C:UsersSAIAnaconda3libsite-packagespandascoreindexing.py in _convert_to_indexer(self, obj, axis, is_setter)
1229 mask = check == -1
1230 if mask.any():
-> 1231 raise KeyError(‘%s not in index’ % objarr[mask])
1232
1233 return _values_from_object(indexer)
KeyError: “[‘year’ ‘model’ ‘price’ ‘mileage’ ‘color’ ‘transmission’] not in index”
This one changes directory to some folder, you should set it to where you store that data file you download from github