In this post we are going to have a look at one of the problems while applying clustering algorithms such as k-means and expectation maximization that is of determining the optimal number of clusters. The problem of determining what will be the best value for the number of clusters is often not very clear from the data set itself. There are a couple of techniques we will walk-through in this post which one can use to help determine the best k-value for a given data set.
To showcase these techniques we will use one of the readily available dataset from the UCI_Dataset_StudentKnowledge.
We will download the dataset in the current R studio environment:
library(readr)
StudentKnowledgeData <- read_csv("YourdownloadFolderPath/StudentKnowledgeData.csv")
View(StudentKnowledgeData)
Pre-processing
This dataset is comma-separated with a header line. We will check for NA values and check if there are any categorical variable to ensure the data is ready for processing for the clustering algorithms. As this data set has low feature vector we will not focus on feature selection aspects but will work with all the available features.
mydata = StudentKnowledgeData
#let us analyze the data to find if categorical variables are there and if so
#transform them.
mydata = as.data.frame(unclass(mydata))
summary(mydata)
dim(mydata)
# We can now remove any records that have NAs
myDataClean = na.omit(mydata)
dim(myDataClean)
summary(myDataClean)
[1] 402 5
STG SCG STR LPR
Min. :0.0000 Min. :0.0000 Min. :0.0100 Min. :0.0000
1st Qu.:0.2000 1st Qu.:0.2000 1st Qu.:0.2700 1st Qu.:0.2500
Median :0.3025 Median :0.3000 Median :0.4450 Median :0.3300
Mean :0.3540 Mean :0.3568 Mean :0.4588 Mean :0.4324
3rd Qu.:0.4800 3rd Qu.:0.5100 3rd Qu.:0.6800 3rd Qu.:0.6500
Max. :0.9900 Max. :0.9000 Max. :0.9500 Max. :0.9900
Once we have done pre-processing to ensure the data is ready for further applications. Let us try and scale and center this dataset.
scaled_data = as.matrix(scale(myDataClean))
Clustering Algorithm – k means a sample example of finding optimal number of clusters in it
Let us try to create the clusters for this data. As we can observe this data doesnot have a pre-defined class/output type defined and so it becomes necessary to know what will be an optimal number of clusters.Let us choose random value of cluster numbers for now and see how the clusters are created.
Let us start with k=3 and check what the results are. R comes with a builtin kmeans() function and we do not need to import any extra package for this.
#Let us apply kmeans for k=3 clusters
kmm = kmeans(scaled_data,3,nstart = 50,iter.max = 15) #we keep number of iter.max=15 to ensure the algorithm converges and nstart=50 to #ensure that atleat 50 random sets are choosen
kmm
K-means clustering with 3 clusters of sizes 93, 167, 142
Cluster means:
STG SCG STR LPR PEG
1 0.573053974 0.3863411 0.2689915 1.3028712 0.1560779
2 -0.315847301 -0.4009366 -0.3931942 -0.1794893 -0.8332218
3 -0.003855777 0.2184978 0.2862481 -0.6421993 0.8776957
Clustering vector:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
...................................................................................
Within cluster sum of squares by cluster:
[1] 394.5076 524.4177 497.7787
(between_SS / total_SS = 29.3 %)
Available components:
[1] "cluster" "centers" "totss" "withinss" "tot.withinss"
[6] "betweenss" "size" "iter" "ifault"
When we check the (between_SS / total_SS) we find it to be low. This ratio actually accounts for the amount of total sum of squares of the data points which is between the clusters. We want to increase this value and as we increase the number of clusters we see it increasing , but we do not want to overfit the data. So we see that with k=401 in this we will have 402 clusters which completely overfits the data. So the idea is to find such a value of k for which the model is not overfitting and at the same time clusters the data as per the actual distribution. Let us now approach how we will solve this problem of finding the best number of clusters.
Elbow Method
The elbow method looks at the percentage of variance explained as a function of the number of clusters: One should choose a number of clusters so that adding another cluster doesn’t give much better modeling of the data. More precisely, if one plots the percentage of variance explained by the clusters against the number of clusters, the first clusters will add much information (explain a lot of variance), but at some point the marginal gain will drop, giving an angle in the graph. The number of clusters is chosen at this point, hence the “elbow criterion”. This “elbow” cannot always be unambiguously identified.
#Elbow Method for finding the optimal number of clusters
set.seed(123)
# Compute and plot wss for k = 2 to k = 15.
k.max <- 15
data <- scaled_data
wss <- sapply(1:k.max,
function(k){kmeans(data, k, nstart=50,iter.max = 15 )$tot.withinss})
wss
plot(1:k.max, wss,
type="b", pch = 19, frame = FALSE,
xlab="Number of clusters K",
ylab="Total within-clusters sum of squares")
[1] 2005.0000 1635.8573 1416.7041 1253.9959 1115.4657 1026.0506 952.4835 887.7202
[9] 830.8277 780.2121 735.6714 693.7745 657.0939 631.5901 608.3576
The plot can be seen below:

Therefore for k=4 the between_ss/total_ss ratio tends to change slowly and remain less changing as compared to other k’s.so for this data k=4 should be a good choice for number of clusters however k=5 also seems to be a potential candidate. So how do we decide what will be the optimal choice. So we look at the second approach which comes with a new package.
Bayesian Inference Criterion for k means
The k-means model is “almost” a Gaussian mixture model and one can construct a likelihood for the Gaussian mixture model and thus also determine information criterion values.
We install the mclust package and we will use the Mclust method of it.Determine the optimal model and number of clusters according to the Bayesian Information Criterion for expectation-maximization, initialized by hierarchical clustering for parameterized Gaussian mixture models. In this method we had set the modelNames parameter to mclust.options(“emModelNames”) so that it includes only those models for evaluation where the number of observation is greater than the dimensions of the dataset here 402>5. The best model selected was EVI (Equal Volume but Variable shape and using Identity Matrix for the eigen values) with number of clusters 3 and 4. So based on this and the previous method the natural number of clusters choice was 4. To further validate this we checked for the BIC(Bayesian Information Criterion for k means) and it seems to validate the findings of Mclust package showing that cluster choice of 3 and 4 are the best and of highest value for this distribution of data.
d_clust <- Mclust(as.matrix(scaled_data), G=1:15,
modelNames = mclust.options("emModelNames"))
d_clust$BIC
plot(d_clust)
Bayesian Information Criterion (BIC):
EII VII EEI VEI EVI VVI EEE EVE
1 -5735.105 -5735.105 -5759.091 -5759.091 -5759.091 -5759.091 -5758.712 -5758.712
2 -5731.019 -5719.188 -5702.988 -5635.324 -5725.379 -5729.256 -5698.095 -5707.733
3 -5726.577 -5707.840 -5648.033 -5618.274 -5580.305 -5620.816 -5693.977 -5632.555
..................................................................................
VEE VVE EEV VEV EVV VVV
1 -5758.712 -5758.712 -5758.712 -5758.712 -5758.712 -5758.712
2 -5704.051 -5735.383 -5742.110 -5743.216 -5752.709 -5753.597
3 -5682.312 -5642.217 -5736.306 -5703.742 -5717.796 -5760.915
..............................................................
Top 3 models based on the BIC criterion:
EVI,3 EVI,4 EEI,5
-5580.305 -5607.980 -5613.077
> plot(d_clust)
Model-based clustering plots:
1: BIC
2: classification
3: uncertainty
4: density
Selection: 1
The plot can be seen below where k=3 and k=4 are the best choices available.
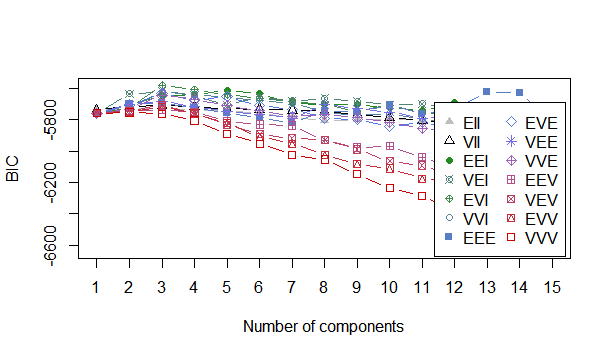
As we can see from the two approaches we can to a certain extent be sure of what an optimal value for the number of clusters can be for a clustering problem. There are few other techniques which can also be used. Let us take at one such approach using the NbClust
NbClust package provides 30 indices for determining the number of clusters and proposes to user the best clustering scheme from the different results obtained by varying all combinations of number of clusters, distance measures, and clustering methods
install.packages("NbClust",dependencies = TRUE)
library(NbClust)
nb <- NbClust(scaled_data, diss=NULL, distance = "euclidean",
min.nc=2, max.nc=5, method = "kmeans",
index = "all", alphaBeale = 0.1)
hist(nb$Best.nc[1,], breaks = max(na.omit(nb$Best.nc[1,])))
There is an important point to here that this method always takes into the majority of the indexes for each cluster size. So it is important to understand which of the indexes are relevant to the data and based on it to determine if the best choice is the maximum value suggested or any other value.
As we see below looking at the Second differences D-index graph we know it is quite clear the best number of clusters is k=4.
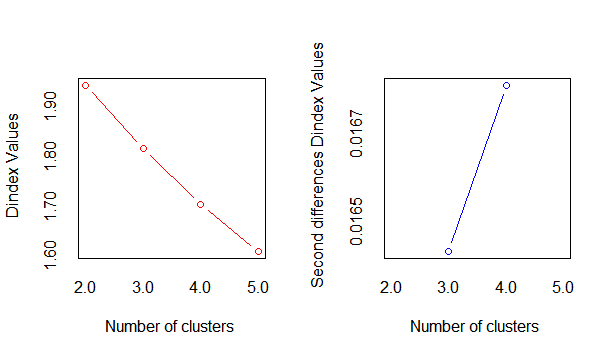
Hope this gives some of the insight how to use different resources in R to determine the optimal number of clusters for relocation algorithms like Kmeans or EM.
There is an explicit formula associated with the elbow method to automatically determine the number of clusters. You can find it in my article, at https://dsc.news/2EYkh3E
How can we know the best number of clusters is k=4 from Second differences D-index graph
If you want to get the same models from the graph of the elbow method after decide the number of clusters, I think it would be better if you use a loop instead the sapply function:
wss <- NA
for (k in 1:k.max) {
set.seed(123)
wss[k] <- kmeans(data, k, nstart=50, iter.max =15)$tot.withinss
}
Can you post the CSV? The UCI data repository directory is blank
I couldn’t upload the csv due to some technical issues, so copying the data here for your reference. Please let me know if this works:
STG SCG STR LPR PEG
0.08 0.08 0.1 0.24 0.9
0.06 0.06 0.05 0.25 0.33
0.1 0.1 0.15 0.65 0.3
0.08 0.08 0.08 0.98 0.24
0.09 0.15 0.4 0.1 0.66
0.1 0.1 0.43 0.29 0.56
0.15 0.02 0.34 0.4 0.01
0.2 0.14 0.35 0.72 0.25
0 0 0.5 0.2 0.85
0.18 0.18 0.55 0.3 0.81
0.06 0.06 0.51 0.41 0.3
0.1 0.1 0.52 0.78 0.34
0.1 0.1 0.7 0.15 0.9
0.2 0.2 0.7 0.3 0.6
0.12 0.12 0.75 0.35 0.8
0.05 0.07 0.7 0.01 0.05
0.1 0.25 0.1 0.08 0.33
0.15 0.32 0.05 0.27 0.29
0.2 0.29 0.25 0.49 0.56
0.12 0.28 0.2 0.78 0.2
0.18 0.3 0.37 0.12 0.66
0.1 0.27 0.31 0.29 0.65
0.18 0.31 0.32 0.42 0.28
0.06 0.29 0.35 0.76 0.25
0.09 0.3 0.68 0.18 0.85
0.04 0.28 0.55 0.25 0.1
0.09 0.255 0.6 0.45 0.25
0.08 0.325 0.62 0.94 0.56
0.15 0.275 0.8 0.21 0.81
0.12 0.245 0.75 0.31 0.59
0.15 0.295 0.75 0.65 0.24
0.1 0.256 0.7 0.76 0.16
0.18 0.32 0.04 0.19 0.82
0.2 0.45 0.28 0.31 0.78
0.06 0.35 0.12 0.43 0.29
0.1 0.42 0.22 0.72 0.26
0.18 0.4 0.32 0.08 0.33
0.09 0.33 0.31 0.26 0
0.19 0.38 0.38 0.49 0.45
0.02 0.33 0.36 0.76 0.1
0.2 0.49 0.6 0.2 0.78
0.14 0.49 0.55 0.29 0.6
0.18 0.33 0.61 0.64 0.25
0.115 0.35 0.65 0.27 0.04
0.17 0.36 0.8 0.14 0.66
0.1 0.39 0.75 0.31 0.62
0.13 0.39 0.85 0.38 0.77
0.18 0.34 0.71 0.71 0.9
0.09 0.51 0.02 0.18 0.67
0.06 0.5 0.09 0.28 0.25
0.23 0.7 0.19 0.51 0.45
0.09 0.55 0.12 0.78 0.05
0.24 0.75 0.32 0.18 0.86
0.18 0.72 0.37 0.29 0.55
0.1 0.6 0.33 0.42 0.26
0.2 0.52 0.36 0.84 0.25
0.09 0.6 0.66 0.19 0.59
0.18 0.51 0.58 0.33 0.82
0.08 0.58 0.6 0.64 0.1
0.09 0.61 0.53 0.75 0.01
0.06 0.77 0.72 0.19 0.56
0.15 0.79 0.78 0.3 0.51
0.2 0.68 0.73 0.48 0.28
0.24 0.58 0.76 0.8 0.28
0.25 0.1 0.03 0.09 0.15
0.32 0.2 0.06 0.26 0.24
0.29 0.06 0.19 0.55 0.51
0.28 0.1 0.12 0.28 0.32
0.3 0.08 0.4 0.02 0.67
0.27 0.12 0.37 0.29 0.58
0.31 0.1 0.41 0.42 0.75
0.29 0.15 0.33 0.66 0.08
0.3 0.2 0.52 0.3 0.53
0.28 0.16 0.69 0.33 0.78
0.255 0.18 0.5 0.4 0.1
0.265 0.06 0.57 0.75 0.1
0.275 0.1 0.72 0.1 0.3
0.245 0.1 0.71 0.26 0.2
0.295 0.2 0.86 0.44 0.28
0.32 0.12 0.79 0.76 0.24
0.295 0.25 0.26 0.12 0.67
0.315 0.32 0.29 0.29 0.62
0.25 0.29 0.15 0.48 0.26
0.27 0.1 0.1 0.7 0.25
0.248 0.3 0.31 0.2 0.03
0.325 0.25 0.38 0.31 0.79
0.27 0.31 0.32 0.41 0.28
0.29 0.29 0.4 0.78 0.18
0.29 0.3 0.52 0.09 0.67
0.258 0.28 0.64 0.29 0.56
0.32 0.255 0.55 0.78 0.34
0.251 0.265 0.57 0.6 0.09
0.288 0.31 0.79 0.23 0.24
0.323 0.32 0.89 0.32 0.8
0.255 0.305 0.86 0.62 0.15
0.295 0.25 0.73 0.77 0.19
0.258 0.25 0.295 0.33 0.77
0.29 0.25 0.29 0.29 0.57
0.243 0.27 0.08 0.42 0.29
0.27 0.28 0.18 0.48 0.26
0.299 0.32 0.31 0.33 0.87
0.3 0.27 0.31 0.31 0.54
0.245 0.26 0.38 0.49 0.27
0.295 0.29 0.31 0.76 0.1
0.29 0.3 0.56 0.25 0.67
0.26 0.28 0.6 0.29 0.59
0.305 0.255 0.63 0.4 0.54
0.32 0.27 0.52 0.81 0.3
0.299 0.295 0.8 0.37 0.84
0.276 0.255 0.81 0.27 0.33
0.258 0.31 0.88 0.4 0.3
0.32 0.28 0.72 0.89 0.58
0.329 0.55 0.02 0.4 0.79
0.295 0.59 0.29 0.31 0.55
0.285 0.64 0.18 0.61 0.45
0.265 0.6 0.28 0.66 0.07
0.315 0.69 0.28 0.8 0.7
0.28 0.78 0.44 0.17 0.66
0.325 0.61 0.46 0.32 0.81
0.28 0.65 0.4 0.65 0.13
0.255 0.75 0.35 0.72 0.25
0.305 0.55 0.5 0.11 0.333
0.3 0.85 0.54 0.25 0.83
0.325 0.9 0.52 0.49 0.76
0.312 0.8 0.67 0.92 0.5
0.299 0.7 0.95 0.22 0.66
0.265 0.76 0.8 0.28 0.28
0.255 0.72 0.72 0.63 0.14
0.295 0.6 0.72 0.88 0.28
0.39 0.05 0.02 0.06 0.34
0.4 0.18 0.26 0.26 0.67
0.45 0.04 0.18 0.55 0.07
0.48 0.12 0.28 0.7 0.71
0.4 0.12 0.41 0.1 0.65
0.41 0.18 0.33 0.31 0.5
0.38 0.1 0.4 0.48 0.26
0.37 0.06 0.32 0.78 0.1
0.41 0.09 0.58 0.18 0.58
0.38 0.01 0.53 0.27 0.3
0.33 0.04 0.5 0.55 0.1
0.42 0.15 0.66 0.78 0.4
0.44 0.08 0.8 0.22 0.56
0.39 0.15 0.81 0.22 0.29
0.42 0.21 0.87 0.56 0.48
0.46 0.2 0.76 0.95 0.65
0.365 0.243 0.19 0.24 0.35
0.33 0.27 0.2 0.33 0.1
0.345 0.299 0.1 0.64 0.13
0.48 0.3 0.15 0.65 0.77
0.49 0.245 0.38 0.14 0.86
0.334 0.295 0.33 0.32 0.3
0.36 0.29 0.37 0.48 0.13
0.39 0.26 0.39 0.77 0.14
0.43 0.305 0.51 0.09 0.64
0.44 0.32 0.55 0.33 0.52
0.45 0.299 0.63 0.36 0.51
0.495 0.276 0.58 0.77 0.83
0.465 0.258 0.73 0.18 0.59
0.475 0.32 0.79 0.31 0.54
0.348 0.329 0.83 0.61 0.18
0.385 0.26 0.76 0.84 0.3
0.445 0.39 0.02 0.24 0.88
0.43 0.45 0.27 0.27 0.89
0.33 0.34 0.1 0.49 0.12
0.4 0.33 0.12 0.3 0.9
0.34 0.4 0.38 0.2 0.61
0.38 0.36 0.46 0.49 0.78
0.35 0.38 0.32 0.6 0.16
0.41 0.49 0.34 0.21 0.92
0.42 0.36 0.63 0.04 0.25
0.43 0.38 0.62 0.33 0.49
0.44 0.33 0.59 0.53 0.85
0.4 0.42 0.58 0.75 0.16
0.46 0.44 0.89 0.12 0.66
0.38 0.39 0.79 0.33 0.3
0.39 0.42 0.83 0.65 0.19
0.49 0.34 0.88 0.75 0.71
0.46 0.64 0.22 0.22 0.6
0.44 0.55 0.11 0.26 0.83
0.365 0.68 0.1 0.63 0.18
0.45 0.65 0.19 0.99 0.55
0.46 0.78 0.38 0.24 0.89
0.37 0.55 0.41 0.29 0.3
0.38 0.59 0.31 0.62 0.2
0.49 0.64 0.34 0.78 0.21
0.495 0.82 0.67 0.01 0.93
0.44 0.69 0.61 0.29 0.57
0.365 0.57 0.59 0.55 0.25
0.49 0.9 0.52 0.9 0.47
0.445 0.7 0.82 0.16 0.64
0.42 0.7 0.72 0.3 0.8
0.37 0.6 0.77 0.4 0.5
0.4 0.61 0.71 0.88 0.67
0.6 0.14 0.22 0.11 0.66
0.55 0.1 0.27 0.25 0.29
0.68 0.19 0.19 0.48 0.1
0.73 0.2 0.07 0.72 0.26
0.78 0.15 0.38 0.18 0.63
0.55 0.1 0.34 0.3 0.1
0.59 0.18 0.31 0.55 0.09
0.64 0.09 0.33 0.65 0.5
0.6 0.19 0.55 0.08 0.1
0.69 0.02 0.62 0.3 0.29
0.78 0.21 0.68 0.65 0.75
0.62 0.14 0.52 0.81 0.15
0.7 0.18 0.88 0.09 0.66
0.75 0.015 0.78 0.31 0.53
0.55 0.17 0.71 0.48 0.11
0.85 0.05 0.91 0.8 0.68
0.78 0.27 0.13 0.14 0.62
0.8 0.29 0.06 0.31 0.51
0.9 0.26 0.19 0.58 0.79
0.76 0.258 0.07 0.83 0.34
0.72 0.32 0.48 0.2 0.6
0.6 0.251 0.39 0.29 0.3
0.52 0.288 0.32 0.5 0.3
0.6 0.31 0.31 0.87 0.58
0.51 0.255 0.55 0.17 0.64
0.58 0.295 0.62 0.28 0.3
0.61 0.258 0.56 0.62 0.24
0.77 0.267 0.59 0.78 0.28
0.79 0.28 0.88 0.2 0.66
0.68 0.27 0.78 0.31 0.57
0.58 0.299 0.73 0.63 0.21
0.77 0.29 0.74 0.82 0.68
0.71 0.475 0.13 0.23 0.59
0.58 0.348 0.06 0.29 0.31
0.88 0.335 0.19 0.55 0.78
0.99 0.49 0.07 0.7 0.69
0.73 0.43 0.32 0.12 0.65
0.61 0.33 0.36 0.28 0.28
0.51 0.4 0.4 0.59 0.23
0.83 0.44 0.49 0.91 0.66
0.66 0.38 0.55 0.15 0.62
0.58 0.35 0.51 0.27 0.3
0.523 0.41 0.55 0.6 0.22
0.66 0.36 0.56 0.4 0.83
0.62 0.37 0.81 0.13 0.64
0.52 0.44 0.82 0.3 0.52
0.5 0.4 0.73 0.62 0.2
0.71 0.46 0.95 0.78 0.86
0.64 0.55 0.15 0.18 0.63
0.52 0.85 0.06 0.27 0.25
0.62 0.62 0.24 0.65 0.25
0.91 0.58 0.26 0.89 0.88
0.62 0.67 0.39 0.1 0.66
0.58 0.58 0.31 0.29 0.29
0.89 0.68 0.49 0.65 0.9
0.72 0.6 0.45 0.79 0.45
0.68 0.63 0.65 0.09 0.66
0.56 0.6 0.6 0.31 0.5
0.54 0.51 0.55 0.64 0.19
0.61 0.78 0.69 0.92 0.58
0.78 0.61 0.71 0.19 0.6
0.54 0.82 0.71 0.29 0.77
0.5 0.75 0.81 0.61 0.26
0.66 0.9 0.76 0.87 0.74
0 0.1 0.5 0.26 0.05
0.05 0.05 0.55 0.6 0.14
0.08 0.18 0.63 0.6 0.85
0.2 0.2 0.68 0.67 0.85
0.22 0.22 0.9 0.3 0.9
0.14 0.14 0.7 0.5 0.3
0.16 0.16 0.8 0.5 0.5
0.12 0.12 0.75 0.68 0.15
0.2 0.2 0.88 0.77 0.8
0.16 0.25 0.01 0.1 0.07
0.11 0.29 0.2 0.05 0.66
0.18 0.26 0.05 0.4 0.04
0.21 0.32 0.25 0.5 0.8
0.13 0.28 0.18 0.75 0.32
0.23 0.29 0.45 0.18 0.88
0.1 0.27 0.35 0.45 0.05
0.22 0.31 0.42 0.88 0.8
0 0.25 0.5 0.09 0.07
0.05 0.29 0.58 0.14 0.32
0.1 0.3 0.58 0.28 0.55
0.2 0.32 0.65 0.31 0.89
0.19 0.28 0.57 0.58 0.17
0.11 0.26 0.56 0.68 0.27
0.12 0.28 0.7 0.16 0.32
0.18 0.29 0.78 0.15 0.61
0.2 0.25 0.7 0.25 0.03
0.16 0.28 0.72 0.27 0.32
0.11 0.3 0.79 0.8 0.32
0.18 0.31 0.81 0.7 0.4
0.1 0.33 0.02 0 0.25
0.18 0.37 0.11 0.28 0.3
0.13 0.4 0.17 0.25 0.38
0.11 0.42 0.38 0.82 0.31
0.22 0.48 0.47 0.78 0.81
0.14 0.38 0.59 0.11 0.32
0.15 0.42 0.6 0.15 0.62
0.09 0.38 0.54 0.69 0.21
0.2 0.49 0.68 0.76 0.78
0.12 0.62 0.21 0.3 0.59
0.14 0.65 0.19 0.26 0.66
0.16 0.51 0.09 0.38 0.1
0.12 0.56 0.13 0.48 0.32
0.2 0.85 0.24 0.79 0.85
0.16 0.52 0.3 0.09 0.11
0.21 0.78 0.42 0.32 0.84
0.08 0.56 0.33 0.4 0.1
0.14 0.61 0.39 0.56 0.56
0.18 0.7 0.41 0.67 0.33
0.22 0.8 0.44 0.78 0.88
0.1 0.6 0.51 0.1 0.01
0.15 0.67 0.56 0.07 0.66
0 0.62 0.52 0.26 0.07
0.11 0.88 0.67 0.66 0.89
0.08 0.56 0.7 0.14 0.1
0.21 0.9 0.9 0.22 0.92
0.08 0.58 0.71 0.27 0.09
0.13 0.62 0.77 0.28 0.31
0.21 0.88 0.87 0.56 0.95
0.22 0.86 0.83 0.89 0.65
0.2 0.78 0.91 0.82 0.85
0.25 0 0.1 0.12 0.37
0.29 0.1 0.17 0.74 0.52
0.3 0.18 0.23 0.9 0.84
0.32 0.02 0.34 0.13 0.31
0.28 0.12 0.38 0.17 0.6
0.26 0.09 0.33 0.28 0.32
0.28 0.16 0.41 0.51 0.56
0.26 0.12 0.34 0.68 0.29
0.31 0.2 0.46 0.78 0.83
0.25 0.05 0.53 0.1 0.12
0.32 0.15 0.66 0.24 0.82
0.28 0.08 0.52 0.25 0.08
0.33 0.2 0.64 0.59 0.94
0.31 0.15 0.58 0.76 0.52
0.28 0.06 0.7 0.27 0.32
0.3 0.16 0.89 0.32 0.95
0.27 0.03 0.76 0.59 0.23
0.32 0.2 0.84 0.81 0.8
0.31 0.32 0.29 0.31 0.96
0.28 0.29 0.19 0.37 0.58
0.32 0.31 0.26 0.83 0.77
0.25 0.28 0.3 0.001 0.25
0.26 0.26 0.31 0.26 0.13
0.27 0.29 0.34 0.28 0.32
0.28 0.28 0.38 0.29 0.62
0.26 0.26 0.35 0.62 0.24
0.3 0.32 0.43 0.87 0.83
0.25 0.26 0.51 0.04 0.13
0.28 0.27 0.56 0.14 0.31
0.31 0.32 0.69 0.3 0.98
0.28 0.29 0.57 0.6 0.27
0.27 0.28 0.59 0.69 0.26
0.25 0.28 0.77 0.11 0.31
0.25 0.54 0.31 0.25 0.08
0.29 0.66 0.35 0.28 0.31
0.29 0.74 0.39 0.41 0.54
0.31 0.82 0.47 0.4 0.99
0.28 0.55 0.38 0.9 0.22
0.33 0.04 0.02 0.12 0.11
0.37 0.09 0.1 0.13 0.32
0.4 0.15 0.16 0.3 0.58
0.37 0.07 0.1 0.41 0.3
0.41 0.11 0.21 0.44 0.57
0.42 0.13 0.15 0.94 0.3
0.41 0.04 0.33 0.26 0.12
0.38 0.09 0.37 0.28 0.32
0.42 0.29 0.14 0.03 0.68
0.4 0.3 0.18 0.29 0.59
0.38 0.33 0.1 0.07 0.4
0.47 0.47 0.25 0.96 0.61
0.41 0.37 0.79 0.12 0.32
0.42 0.39 0.78 0.32 0.2
0.36 0.52 0.07 0.1 0.15
0.4 0.59 0.77 0.99 0.24
0.43 0.65 0.76 0.94 0.29
0.6 0.08 0.13 0.14 0.32
0.8 0.24 0.23 0.29 0.98
0.65 0.09 0.16 0.49 0.31
0.68 0.16 0.2 0.59 0.6
0.75 0.22 0.24 0.96 0.62
0.87 0.23 0.25 0.85 0.8
0.52 0.08 0.33 0.07 0.09
0.62 0.12 0.36 0.36 0.32
0.68 0.15 0.58 0.35 0.6
0.54 0.25 0.07 0.09 0.11
0.9 0.31 0.24 0.3 0.97
0.56 0.27 0.11 0.59 0.22
0.85 0.32 0.22 0.87 0.79
0.52 0.28 0.32 0.1 0.1
0.78 0.47 0.24 0.3 0.93
0.56 0.35 0.1 0.62 0.23
0.61 0.38 0.09 0.38 0.3
0.78 0.47 0.29 0.98 0.59
0.58 0.4 0.32 0.22 0.24
0.68 0.43 0.6 0.47 0.55
0.57 0.37 0.75 0.27 0.32
0.62 0.56 0.11 0.24 0.22
0.64 0.58 0.14 0.32 0.21
0.64 0.59 0.12 0.58 0.24
0.68 0.61 0.34 0.31 0.23
0.9 0.78 0.62 0.32 0.89
0.85 0.82 0.66 0.83 0.83
0.56 0.6 0.77 0.13 0.32
0.66 0.68 0.81 0.57 0.57
0.68 0.64 0.79 0.97 0.24
Please use Text_to_Column Option in Data Tab in MS excel and use space to convert it into table and then use it. Hope this helps you.
Thank you!
Rich