Assume you are given a dataset for a large bank and you are tasked to come up with a credit risk score for each customer.You have just been briefed that you are going to work on this project and you have to come up with a prototype demonstrating how this problem could be solved.
Approach
The credit risk scoring is a very complicated process with a lot of due diligence on data, model reviews internal controls and sign offs. As a first step you could follow the steps outlined below with the accompanying code to create a straw man version of your approach. You can find full code here: Link
Data Analysis
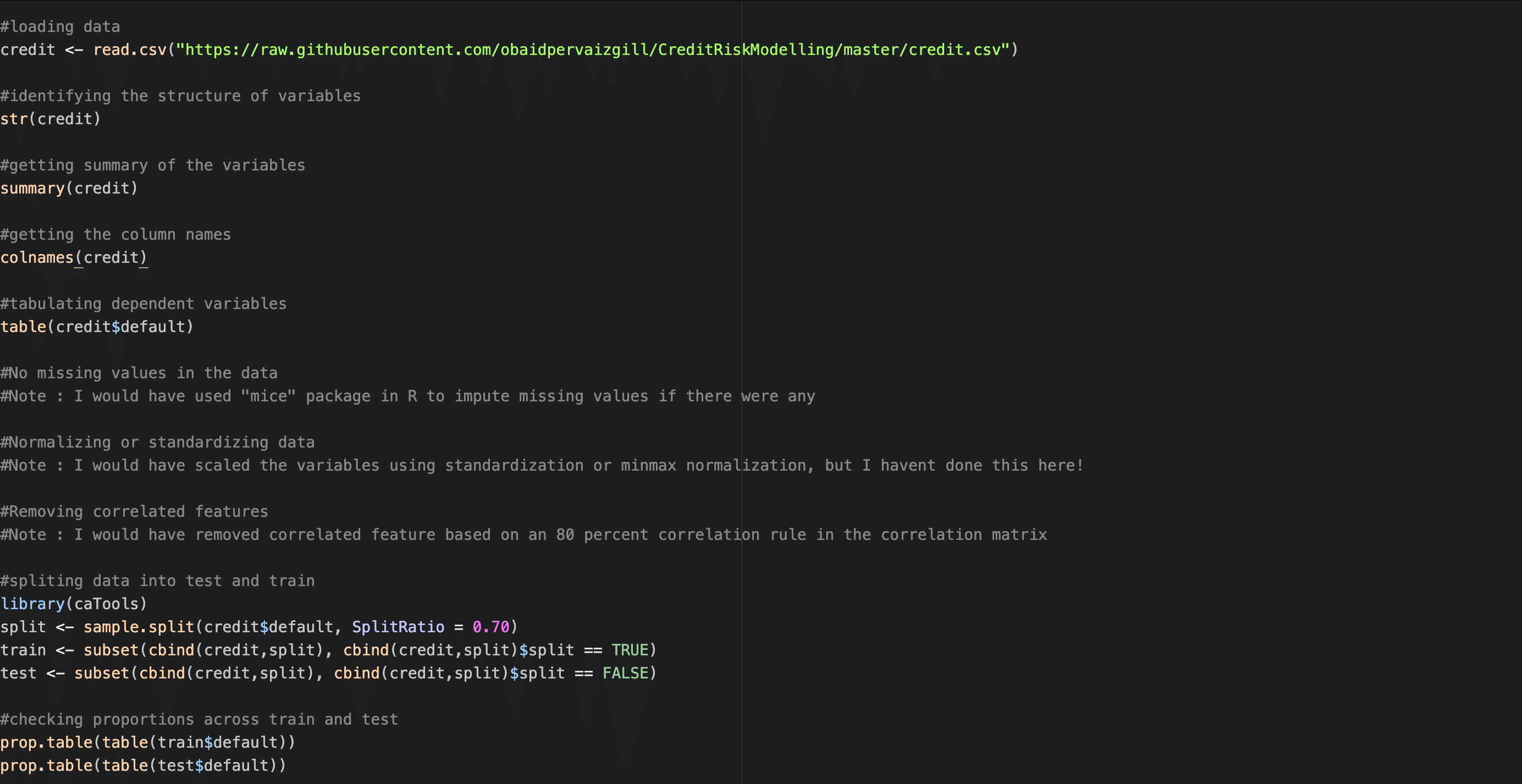
Logistic Regression
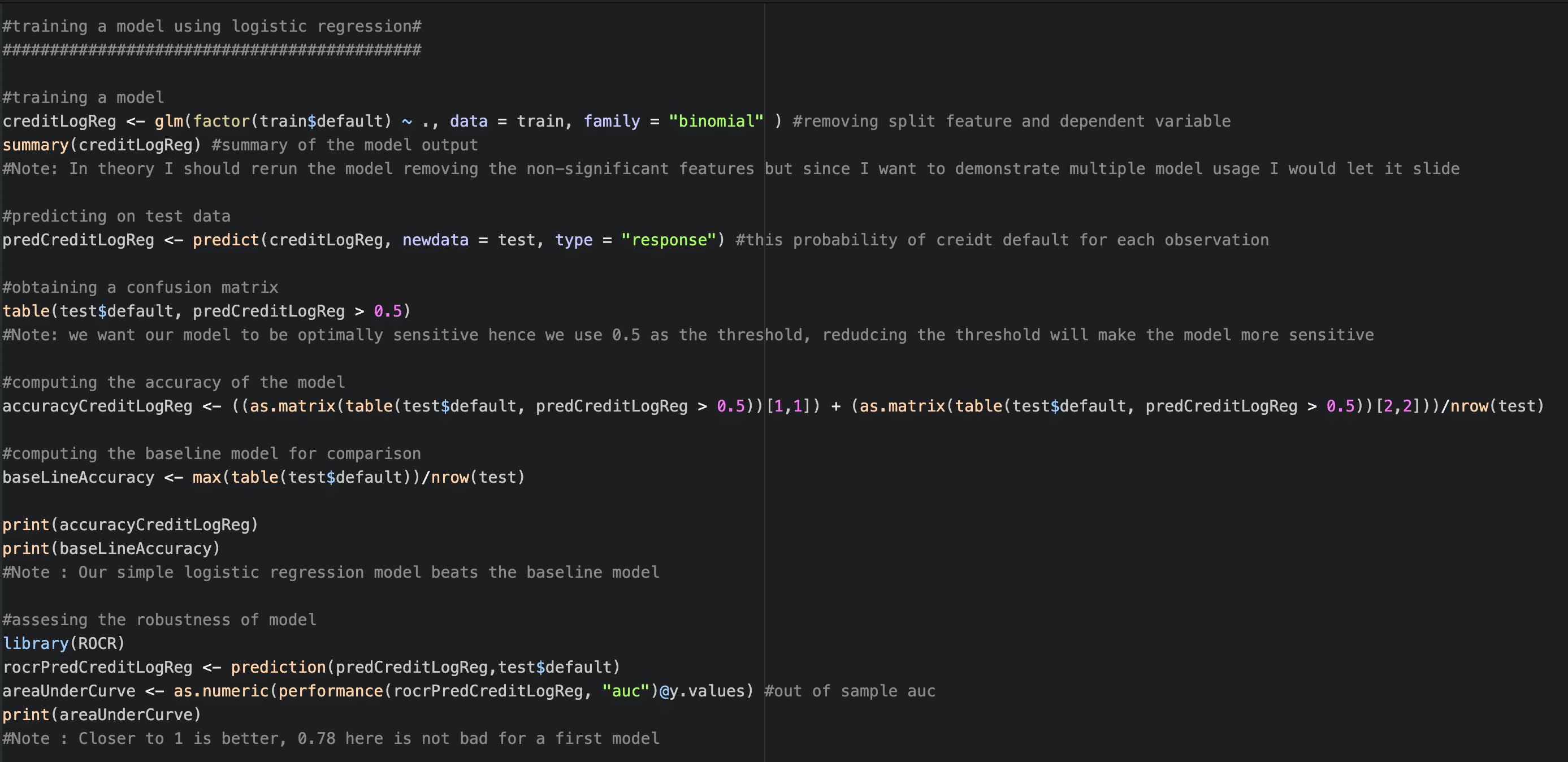
The second step in your prototype will be to train an explainable model, such as a logistic regression model so that you can identify and explain the driving variables.
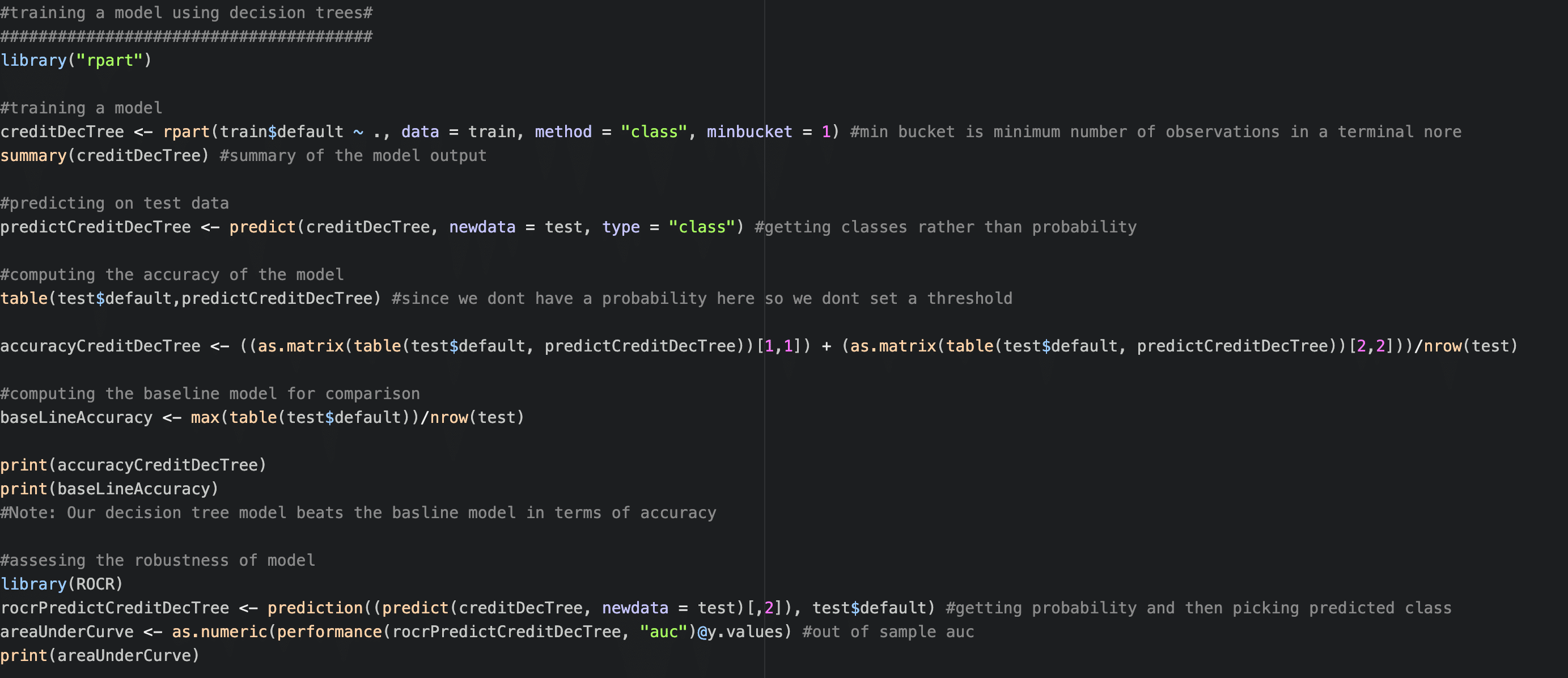
Decision Tree
The third step in your prototype will be to train a more complicated model to assess if you can improve over your explainable model through additional tuning as well.
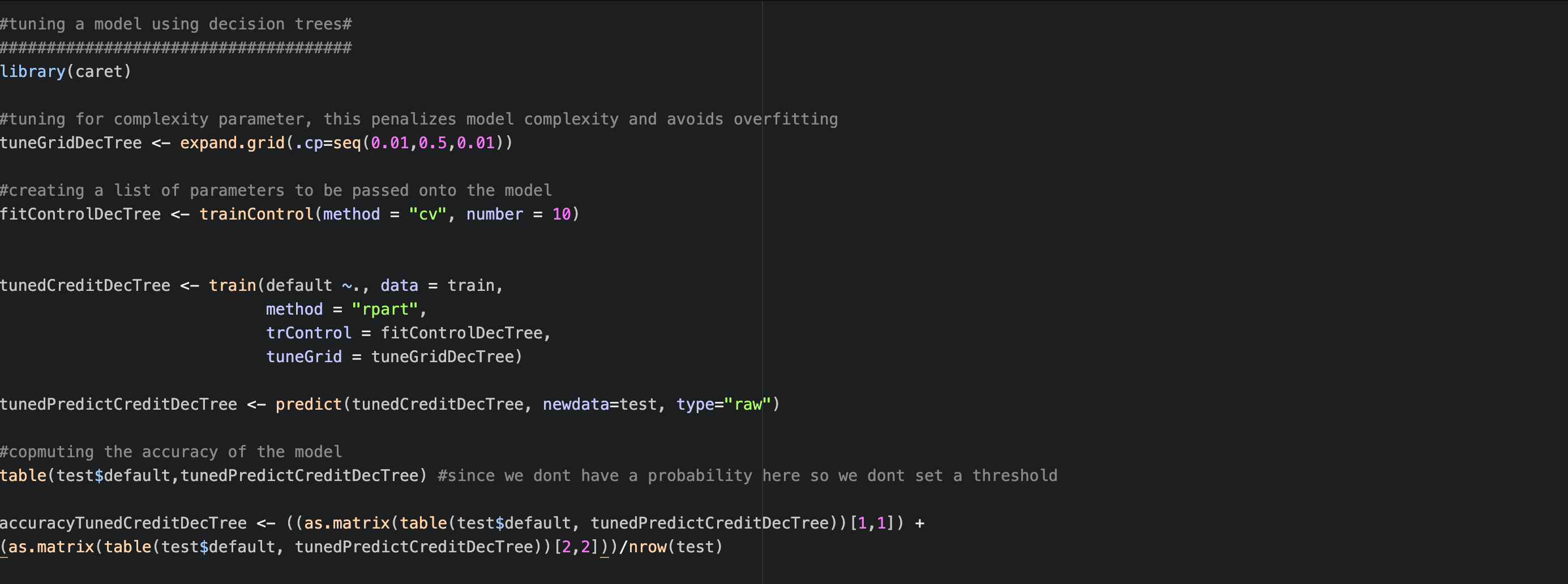
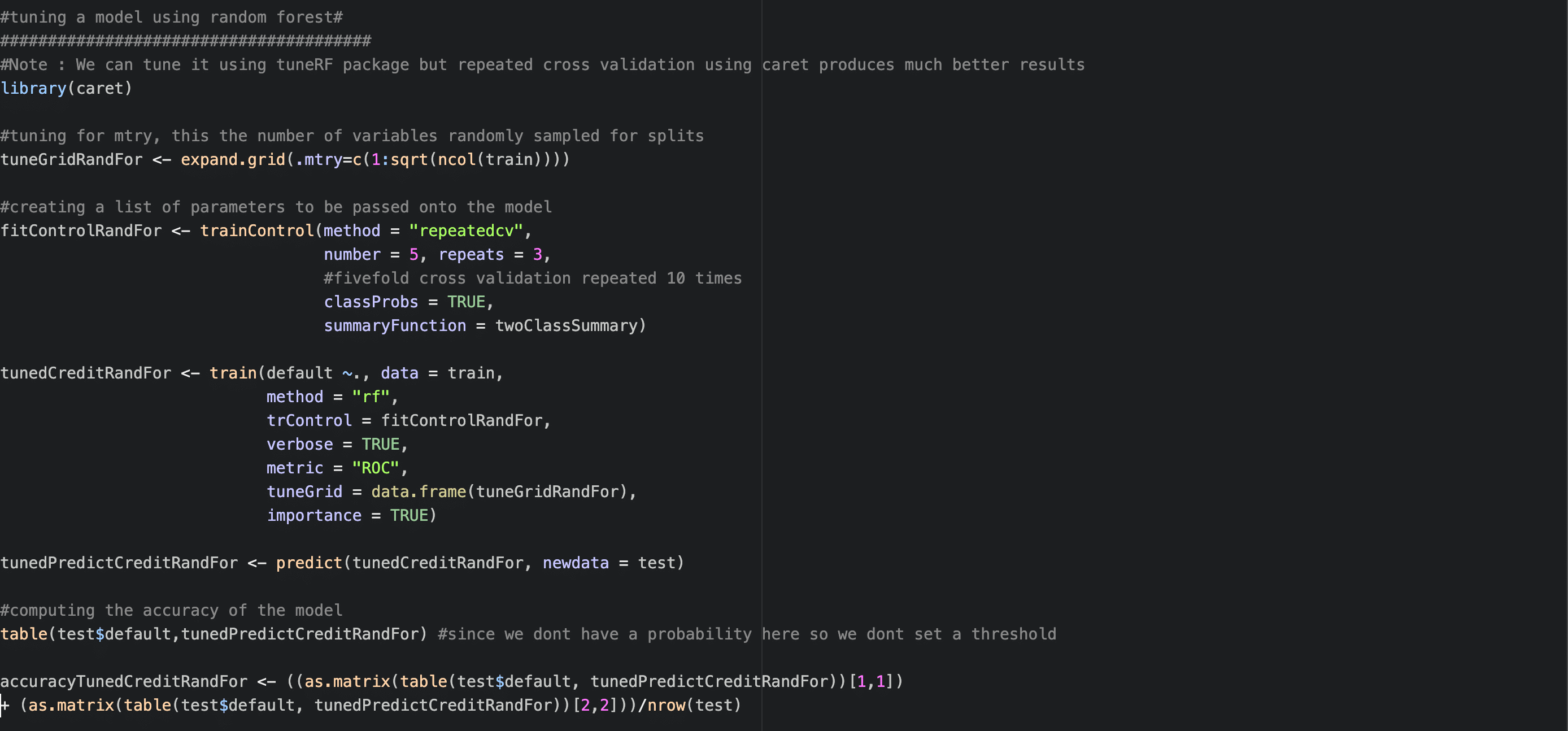
Tuning can be done as follows:
Random Forest
The final step in your prototype will be to train using a highly robust and more black box model to assess if you can improve over your existing approaches, to see if it is worthwhile to pursue this path.
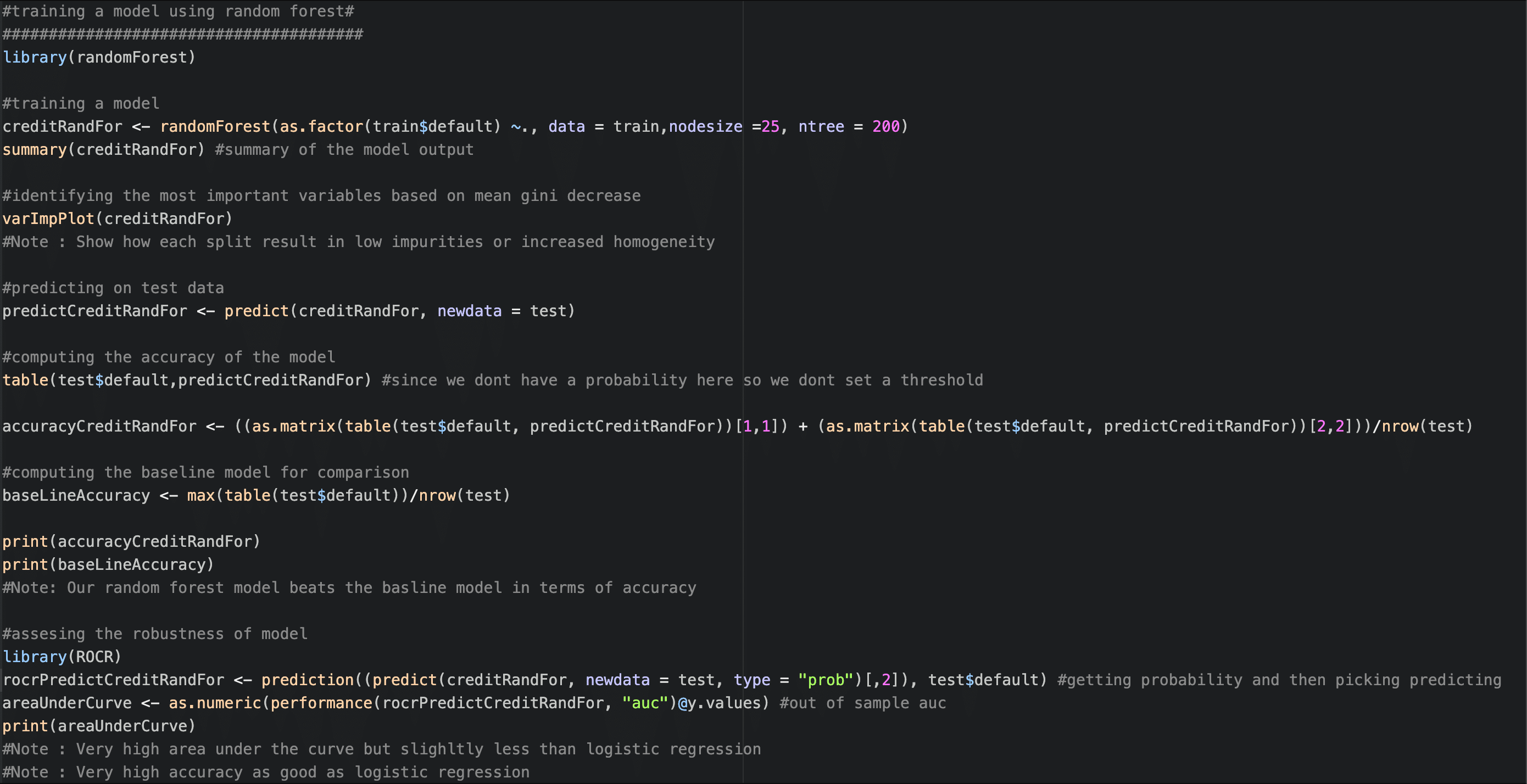
Tuning can be done as follows:
Conclusion
Depending on the problem you are trying to solve, you could pick a model that serves your case, simplest is always the better unless the complicated one is significantly better. Also note that while there may be a temptation to jump into models, most improvement in model performance come from data wrangling and creating new features for your models.