In statistics, an outlier is defined as an observation which stands far away from the most of other observations. Often an outlier is present due to the measurements error. Therefore, one of the most important tasks in data analysis is to identify and only if it is necessary to remove the outlier.
There are different methods to detect the outliers, including standard deviation approach and Tukey’s method which use interquartile (IQR) range approach. In this post, I will use the Tukey’s method because I like that it is not dependent on the distribution of data. Moreover, the Tukey’s method ignores the mean and standard deviation, which are influenced by the extreme values (outliers).
The Script
I created a script to identify, describe, plot and remove (if necessary) the outliers. To detect the outliers I use the command boxplot.stats()$out which use the Tukey’s method to identify the outliers ranged above and below the 1.5*IQR. To describe the data I preferred to show the number (%) of outliers and the mean of the outliers in the dataset. I also show the mean of data with and without outliers. Regarding the plot, I think that boxplot and histogram are the best for presenting the outliers. In the script below, I will plot the data with and without the outliers. Finally, with help from Selva, I added a question to ask whether to keep or remove the outliers in data. If the answer is yes then outliers will be replaced with NA.
Here it is the function and an example is below:
outlierKD <- function(dt, var) {
var_name <- eval(substitute(var),eval(dt))
tot <- sum(!is.na(var_name))
na1 <- sum(is.na(var_name))
m1 <- mean(var_name, na.rm = T)
par(mfrow=c(2, 2), oma=c(0,0,3,0))
boxplot(var_name, main="With outliers")
hist(var_name, main="With outliers", xlab=NA, ylab=NA)
outlier <- boxplot.stats(var_name)$out
mo <- mean(outlier)
var_name <- ifelse(var_name %in% outlier, NA, var_name)
boxplot(var_name, main="Without outliers")
hist(var_name, main="Without outliers", xlab=NA, ylab=NA)
title("Outlier Check", outer=TRUE)
na2 <- sum(is.na(var_name))
message("Outliers identified: ", na2 - na1, " from ", tot, " observations")
message("Proportion (%) of outliers: ", (na2 - na1) / tot*100)
message("Mean of the outliers: ", mo)
m2 <- mean(var_name, na.rm = T)
message("Mean without removing outliers: ", m1)
message("Mean if we remove outliers: ", m2)
response <- readline(prompt="Do you want to remove outliers and to replace with NA? [yes/no]: ")
if(response == "y" | response == "yes"){
dt[as.character(substitute(var))] <- invisible(var_name)
assign(as.character(as.list(match.call())$dt), dt, envir = .GlobalEnv)
message("Outliers successfully removed", "\n")
return(invisible(dt))
} else{
message("Nothing changed", "\n")
return(invisible(var_name))
}
}To call the function run the code below (make sure you replace the dat with your dataset name, and variable with your variable name in the code below):
source("https://goo.gl/4mthoF")
outlierKD(dat, variable)Here it is an example of mtcars dataset:
source("https://goo.gl/4mthoF")
outlierKD(mtcars, hp)
yes
Outliers identified: 1 from 32 observations
Proportion (%) of outliers: 3.125
Mean of the outliers: 335
Mean without removing outliers: 146.6875
Mean if we remove outliers: 140.612903225806
Do you want to remove outliers and to replace with NA? [yes/no]: yes
Outliers successfully removedHere it is an example of the plot:
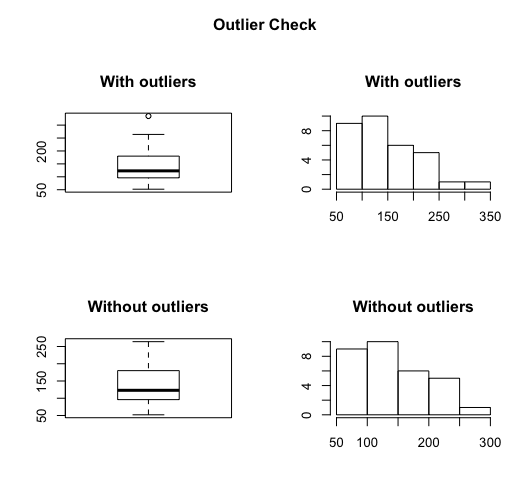
Finally, I strongly suggest thinking carefully before you decide to remove an outlier from your data. An outlier is not necessary a value which stands away from the mean but is a value which wrongly was added to your data.
If you have questions please leave a comment below.