Recently I wanted to extract a table from a pdf file so that I could work with the table in R. Specifically, I wanted to get data on layoffs in California from the California Employment Development Department. The EDD publishes a list of all of the layoffs in the state that fall under the WARN act here. Unfortunately, the tables are available only in pdf format. I wanted an interactive version of the data that I could work with in R and export to a csv file. Fortunately, the tabulizer package in R makes this a cinch. In this post, I will use this scenario as a working example to show how to extract data from a pdf file using the tabulizer package in R.
The link to the pdf gets updated often, so here I’ve provided the pdf (link is below) as downloaded from the site on November 29, 2016:
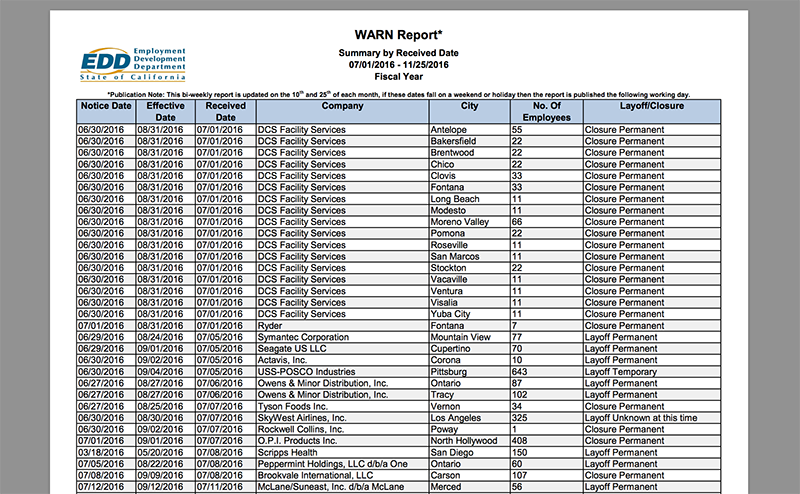
Preview of the PDF (link is below):
First, we will need to load the tabulizer package as well as dplyr.
library(tabulizer) library(dplyr)
Next we will use the extract_tables() function from tabulizer. First, I specify the url of the pdf file from which I want to extract a table. This pdf link includes the most recent data, covering the period from July 1, 2016 to November 25, 2016. I am using the default parameters for extract_tables. These are guess and method. I’ll leave guess set to TRUE, which tells tabulizer that we want it to figure out the locations of the tables on its own. We could set this to FALSE if we want to have more granular control, but for this application we don’t need to. We leave the method argument set to “matrix”, which will return a list of matrices (one for each pdf page). This could also be set to return data frames instead.
# Location of WARN notice pdf file location <- 'http://www.edd.ca.gov/jobs_and_training/warn/WARN-Report-for-7-1-2016-to-10-25-2016.pdf' # Extract the table out <- extract_tables(location)
Now we have a list object called out, with each element a matrix representation of a page of the pdf table. We want to combine these into a single data matrix containing all of the data. We can do so most elegantly by combining do.call and rbind, passing it our list of matrices. Notice that I am excluding the last page here. The final page is the totals and summary information. We don’t need that.
final <- do.call(rbind, out[-length(out)])
After doing so, the first three rows of the matrix contain the headers, which have not been formatted well since they take up multiple rows of the pdf table. Let’s fix that. Here I turn the matrix into a data.frame dropping the first three rows. Then I create a character vector containing the formatted headers and use that as the column names.
# table headers get extracted as rows with bad formatting. Dump them.
final <- as.data.frame(final[3:nrow(final), ])
# Column names
headers <- c('Notice.Date', 'Effective.Date', 'Received.Date', 'Company', 'City',
'No.of.Employees', 'Layoff/Closure')
# Apply custom column names
names(final) <- headers
We now have a data.frame of all of the California layoffs. A quick glance at the first few rows:
head(final) Notice.Date Effective.Date Received.Date Company City No.of.Employees Layoff/Closure 1 2016-06-30 2016-08-31 2016-07-01 DCS Facility Services Antelope 55 Closure Permanent 2 2016-06-30 2016-08-31 2016-07-01 DCS Facility Services Bakersfield 22 Closure Permanent 3 2016-06-30 2016-08-31 2016-07-01 DCS Facility Services Brentwood 22 Closure Permanent 4 2016-06-30 2016-08-31 2016-07-01 DCS Facility Services Chico 22 Closure Permanent 5 2016-06-30 2016-08-31 2016-07-01 DCS Facility Services Clovis 33 Closure Permanent 6 2016-06-30 2016-08-31 2016-07-01 DCS Facility Services Fontana 33 Closure Permanent
In order to manipulate the data properly , we will probably want to change the date column to a Date object as well as convert the No.of.Employees column to numeric. Here I do so using dplyr.
# These dplyr steps are not strictly necessary for dumping to csv, but useful if further data
# manipulation in R is required.
final <- final %>%
# Convert date columns to date objects
mutate_each(funs(as.Date(., format='%m/%d/%Y')), Notice.Date, Effective.Date, Received.Date) %>%
# Convert No.of.Employees to numeric
mutate(No.of.Employees = as.numeric(levels(No.of.Employees)[No.of.Employees]))
Last of all, I finish up by writing the final table to csv so that I can load it for later use.
# Write final table to disk write.csv(final, file='CA_WARN.csv', row.names=FALSE)
I have found the tabulizer package to be wonderfully easy to use. Much of the process of extracting the data and tables from pdfs is abstracted away from the user. This was a very simple example, however if one requires more finely-tuned control of how tables are extracted, the extract_tables function has a lot of additional arguments to tweak to one’s liking. I encourage you to take a look for yourself.
You can find the code for this post on my Github.